 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePivot Through English: Reliably Answering Multilingual Questions without Document Retrieval
Dec 28, 2020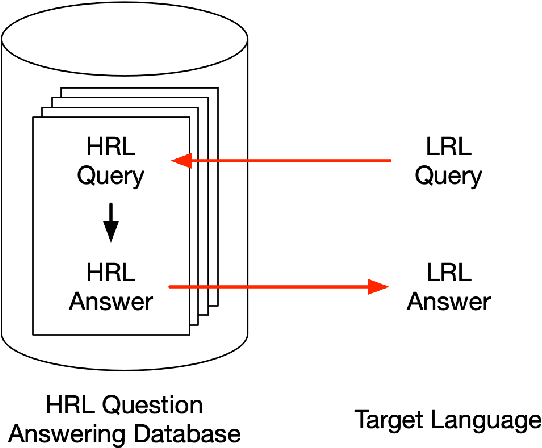

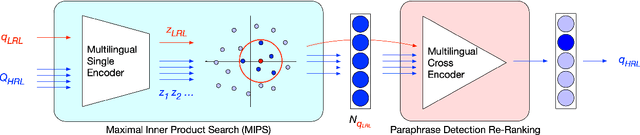
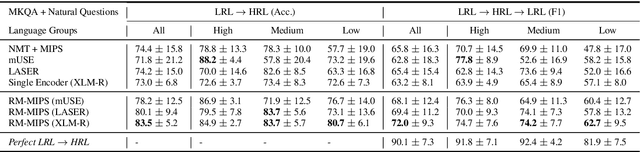
Existing methods for open-retrieval question answering in lower resource languages (LRLs) lag significantly behind English. They not only suffer from the shortcomings of non-English document retrieval, but are reliant on language-specific supervision for either the task or translation. We formulate a task setup more realistic to available resources, that circumvents document retrieval to reliably transfer knowledge from English to lower resource languages. Assuming a strong English question answering model or database, we compare and analyze methods that pivot through English: to map foreign queries to English and then English answers back to target language answers. Within this task setup we propose Reranked Multilingual Maximal Inner Product Search (RM-MIPS), akin to semantic similarity retrieval over the English training set with reranking, which outperforms the strongest baselines by 2.7% on XQuAD and 6.2% on MKQA. Analysis demonstrates the particular efficacy of this strategy over state-of-the-art alternatives in challenging settings: low-resource languages, with extensive distractor data and query distribution misalignment. Circumventing retrieval, our analysis shows this approach offers rapid answer generation to almost any language off-the-shelf, without the need for any additional training data in the target language.
How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
Oct 05, 2020

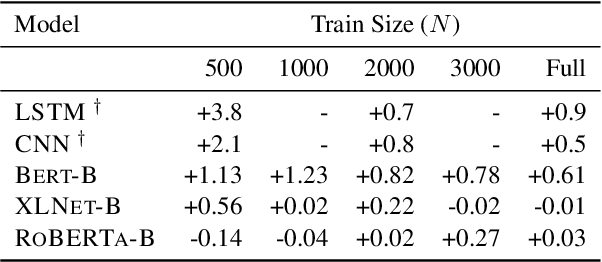
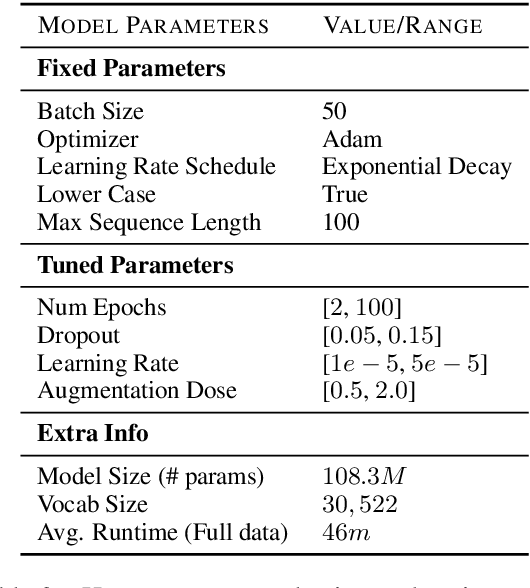
Task-agnostic forms of data augmentation have proven widely effective in computer vision, even on pretrained models. In NLP similar results are reported most commonly for low data regimes, non-pretrained models, or situationally for pretrained models. In this paper we ask how effective these techniques really are when applied to pretrained transformers. Using two popular varieties of task-agnostic data augmentation (not tailored to any particular task), Easy Data Augmentation (Wei and Zou, 2019) and Back-Translation (Sennrichet al., 2015), we conduct a systematic examination of their effects across 5 classification tasks, 6 datasets, and 3 variants of modern pretrained transformers, including BERT, XLNet, and RoBERTa. We observe a negative result, finding that techniques which previously reported strong improvements for non-pretrained models fail to consistently improve performance for pretrained transformers, even when training data is limited. We hope this empirical analysis helps inform practitioners where data augmentation techniques may confer improvements.
On the Transferability of Minimal Prediction Preserving Inputs in Question Answering
Sep 17, 2020



Recent work (Feng et al., 2018) establishes the presence of short, uninterpretable input fragments that yield high confidence and accuracy in neural models. We refer to these as Minimal Prediction Preserving Inputs (MPPIs). In the context of question answering, we investigate competing hypotheses for the existence of MPPIs, including poor posterior calibration of neural models, lack of pretraining, and "dataset bias" (where a model learns to attend to spurious, non-generalizable cues in the training data). We discover a perplexing invariance of MPPIs to random training seed, model architecture, pretraining, and training domain. MPPIs demonstrate remarkable transferability across domains - closing half the gap between models' performance on comparably short queries and original queries. Additionally, penalizing over-confidence on MPPIs fails to improve either generalization or adversarial robustness. These results suggest the interpretability of MPPIs is insufficient to characterize generalization capacity of these models. We hope this focused investigation encourages a more systematic analysis of model behavior outside of the human interpretable distribution of examples.