 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Words: On the Inner Lexicon of LLMs
Oct 10, 2024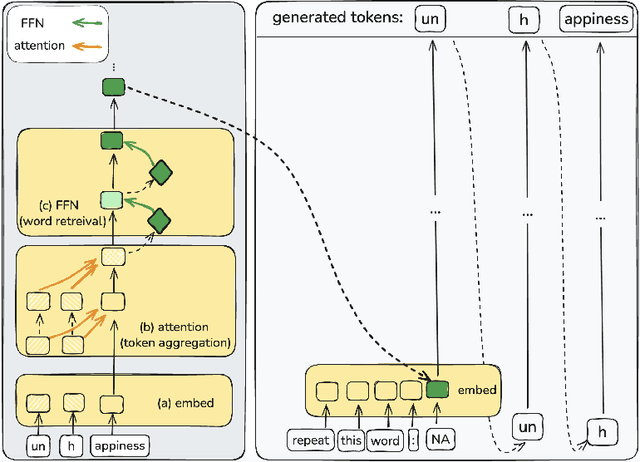
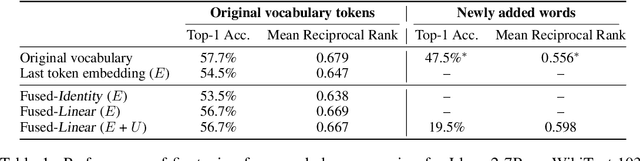
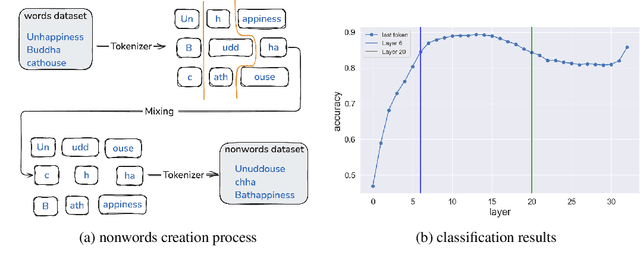

Natural language is composed of words, but modern LLMs process sub-words as input. A natural question raised by this discrepancy is whether LLMs encode words internally, and if so how. We present evidence that LLMs engage in an intrinsic detokenization process, where sub-word sequences are combined into coherent word representations. Our experiments show that this process takes place primarily within the early and middle layers of the model. They also show that it is robust to non-morphemic splits, typos and perhaps importantly-to out-of-vocabulary words: when feeding the inner representation of such words to the model as input vectors, it can "understand" them despite never seeing them during training. Our findings suggest that LLMs maintain a latent vocabulary beyond the tokenizer's scope. These insights provide a practical, finetuning-free application for expanding the vocabulary of pre-trained models. By enabling the addition of new vocabulary words, we reduce input length and inference iterations, which reduces both space and model latency, with little to no loss in model accuracy.
Transformers are Multi-State RNNs
Jan 11, 2024



Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only transformers can in fact be conceptualized as infinite multi-state RNNs - an RNN variant with unlimited hidden state size. We further show that pretrained transformers can be converted into $\textit{finite}$ multi-state RNNs by fixing the size of their hidden state. We observe that several existing transformers cache compression techniques can be framed as such conversion policies, and introduce a novel policy, TOVA, which is simpler compared to these policies. Our experiments with several long range tasks indicate that TOVA outperforms all other baseline policies, while being nearly on par with the full (infinite) model, and using in some cases only $\frac{1}{8}$ of the original cache size. Our results indicate that transformer decoder LLMs often behave in practice as RNNs. They also lay out the option of mitigating one of their most painful computational bottlenecks - the size of their cache memory. We publicly release our code at https://github.com/schwartz-lab-NLP/TOVA.
SERRANT: a syntactic classifier for English Grammatical Error Types
Apr 07, 2021SERRANT is a system and code for automatic classification of English grammatical errors that combines SErCl and ERRANT. SERRANT uses ERRANT's annotations when they are informative and those provided by SErCl otherwise.