 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging World Events to Predict E-Commerce Consumer Demand under Anomaly
May 22, 2024Consumer demand forecasting is of high importance for many e-commerce applications, including supply chain optimization, advertisement placement, and delivery speed optimization. However, reliable time series sales forecasting for e-commerce is difficult, especially during periods with many anomalies, as can often happen during pandemics, abnormal weather, or sports events. Although many time series algorithms have been applied to the task, prediction during anomalies still remains a challenge. In this work, we hypothesize that leveraging external knowledge found in world events can help overcome the challenge of prediction under anomalies. We mine a large repository of 40 years of world events and their textual representations. Further, we present a novel methodology based on transformers to construct an embedding of a day based on the relations of the day's events. Those embeddings are then used to forecast future consumer behavior. We empirically evaluate the methods over a large e-commerce products sales dataset, extracted from eBay, one of the world's largest online marketplaces. We show over numerous categories that our method outperforms state-of-the-art baselines during anomalies.
Temporal Attention for Language Models
Feb 04, 2022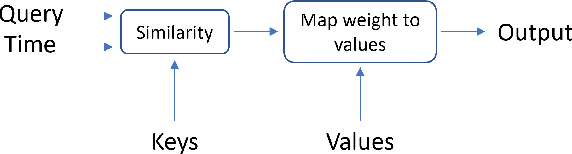

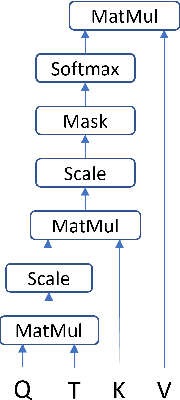
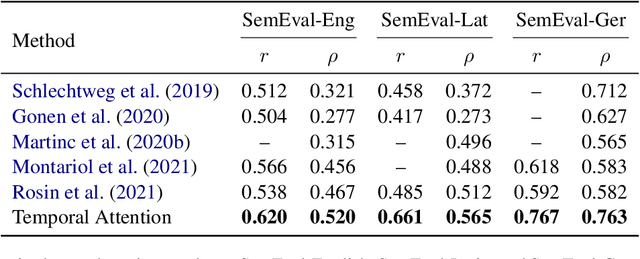
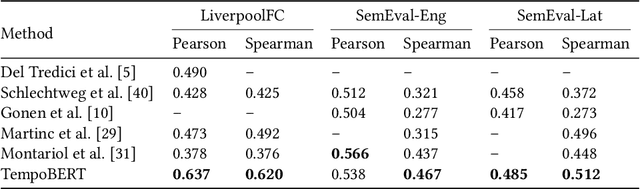
Pretrained language models based on the transformer architecture have shown great success in NLP. Textual training data often comes from the web and is thus tagged with time-specific information, but most language models ignore this information. They are trained on the textual data alone, limiting their ability to generalize temporally. In this work, we extend the key component of the transformer architecture, i.e., the self-attention mechanism, and propose temporal attention - a time-aware self-attention mechanism. Temporal attention can be applied to any transformer model and requires the input texts to be accompanied with their relevant time points. It allows the transformer to capture this temporal information and create time-specific contextualized word representations. We leverage these representations for the task of semantic change detection; we apply our proposed mechanism to BERT and experiment on three datasets in different languages (English, German, and Latin) that also vary in time, size, and genre. Our proposed model achieves state-of-the-art results on all the datasets.
Time Masking for Temporal Language Models
Oct 22, 2021

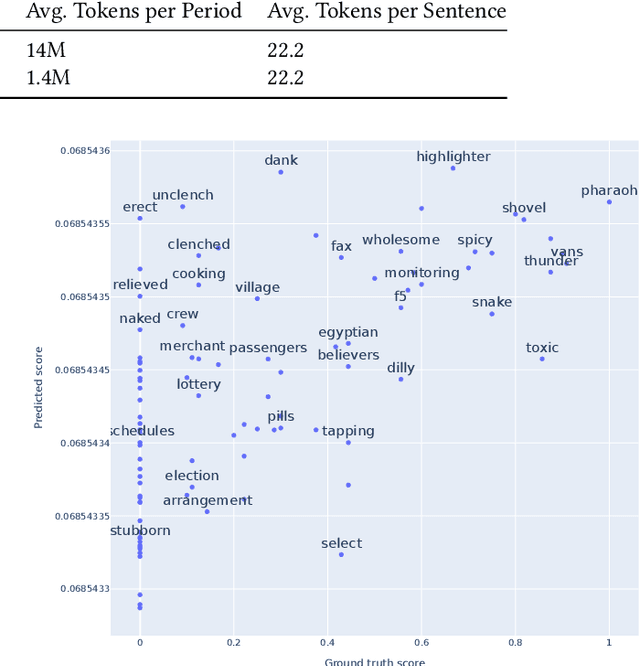
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
Event-Driven Query Expansion
Dec 22, 2020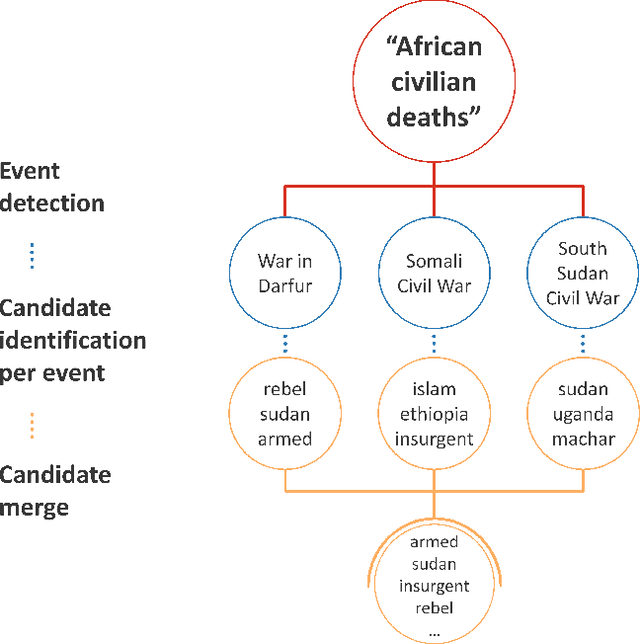
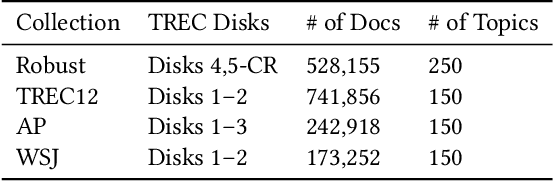
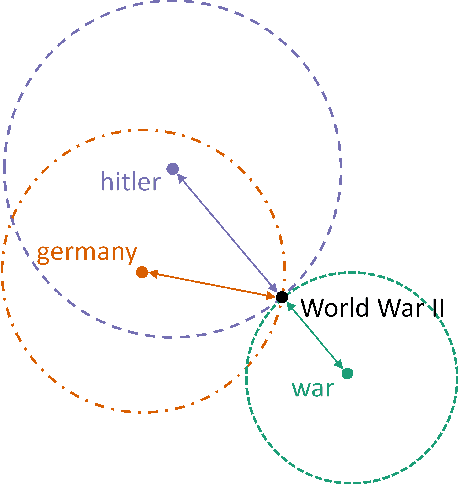
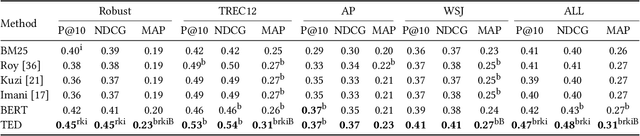
A significant number of event-related queries are issued in Web search. In this paper, we seek to improve retrieval performance by leveraging events and specifically target the classic task of query expansion. We propose a method to expand an event-related query by first detecting the events related to it. Then, we derive the candidates for expansion as terms semantically related to both the query and the events. To identify the candidates, we utilize a novel mechanism to simultaneously embed words and events in the same vector space. We show that our proposed method of leveraging events improves query expansion performance significantly compared with state-of-the-art methods on various newswire TREC datasets.
Generating Timelines by Modeling Semantic Change
Sep 21, 2019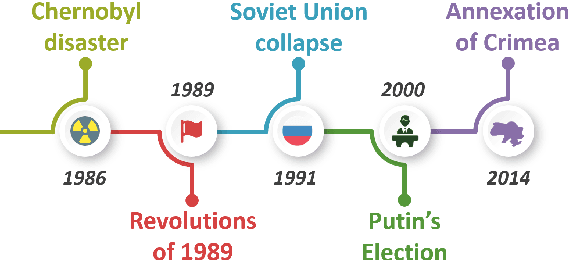
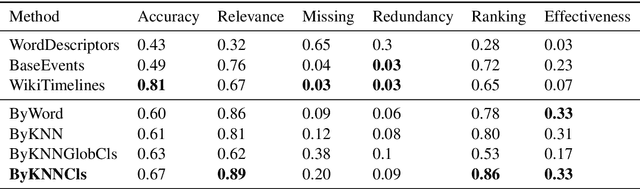
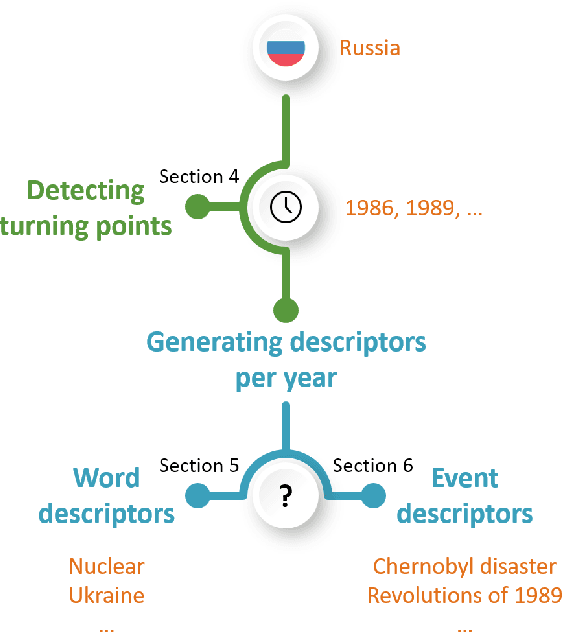
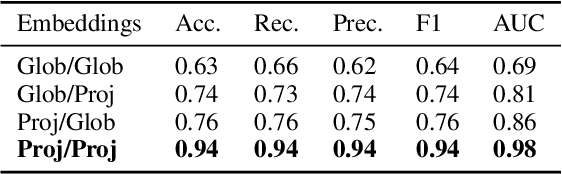
Though languages can evolve slowly, they can also react strongly to dramatic world events. By studying the connection between words and events, it is possible to identify which events change our vocabulary and in what way. In this work, we tackle the task of creating timelines - records of historical "turning points", represented by either words or events, to understand the dynamics of a target word. Our approach identifies these points by leveraging both static and time-varying word embeddings to measure the influence of words and events. In addition to quantifying changes, we show how our technique can help isolate semantic changes. Our qualitative and quantitative evaluations show that we are able to capture this semantic change and event influence.
Learning Word Relatedness over Time
Jul 30, 2017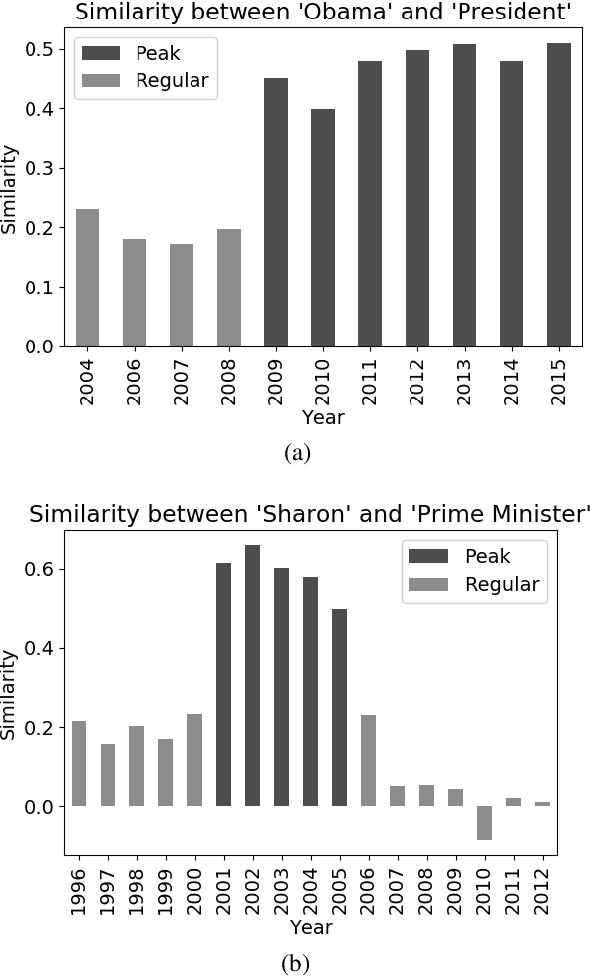
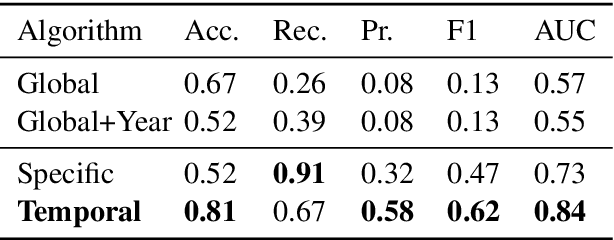
Search systems are often focused on providing relevant results for the "now", assuming both corpora and user needs that focus on the present. However, many corpora today reflect significant longitudinal collections ranging from 20 years of the Web to hundreds of years of digitized newspapers and books. Understanding the temporal intent of the user and retrieving the most relevant historical content has become a significant challenge. Common search features, such as query expansion, leverage the relationship between terms but cannot function well across all times when relationships vary temporally. In this work, we introduce a temporal relationship model that is extracted from longitudinal data collections. The model supports the task of identifying, given two words, when they relate to each other. We present an algorithmic framework for this task and show its application for the task of query expansion, achieving high gain.