 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Simulator
Paper and Code
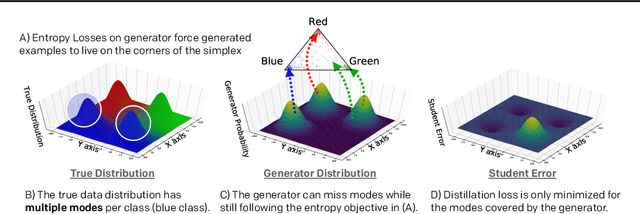
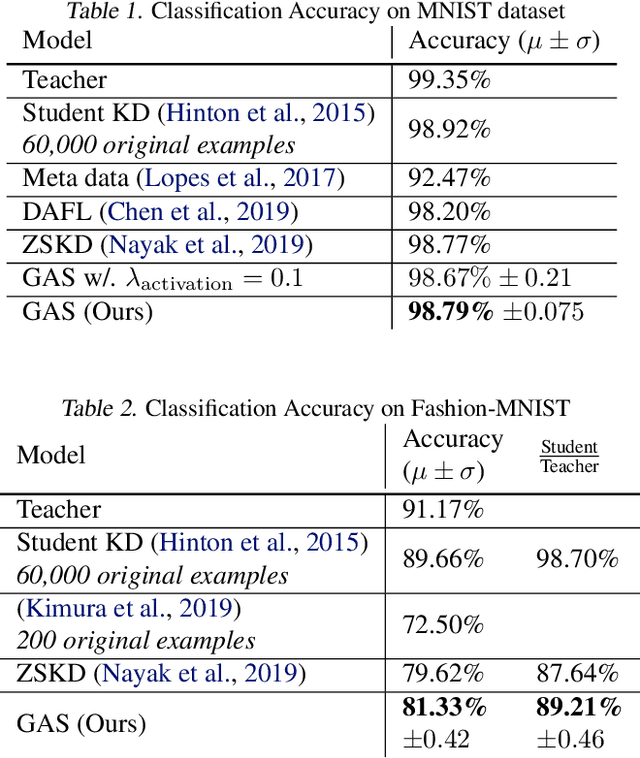

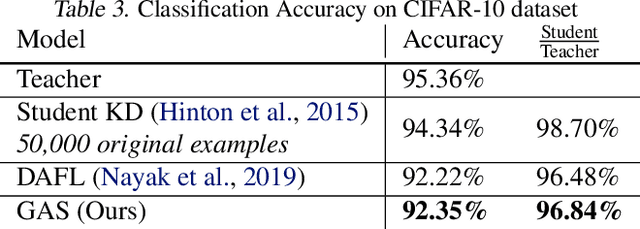
Knowledge distillation between machine learning models has opened many new avenues for parameter count reduction, performance improvements, or amortizing training time when changing architectures between the teacher and student network. In the case of reinforcement learning, this technique has also been applied to distill teacher policies to students. Until now, policy distillation required access to a simulator or real world trajectories. In this paper we introduce a simulator-free approach to knowledge distillation in the context of reinforcement learning. A key challenge is having the student learn the multiplicity of cases that correspond to a given action. While prior work has shown that data-free knowledge distillation is possible with supervised learning models by generating synthetic examples, these approaches to are vulnerable to only producing a single prototype example for each class. We propose an extension to explicitly handle multiple observations per output class that seeks to find as many exemplars as possible for a given output class by reinitializing our data generator and making use of an adversarial loss. To the best of our knowledge, this is the first demonstration of simulator-free knowledge distillation between a teacher and a student policy. This new approach improves over the state of the art on data-free learning of student networks on benchmark datasets (MNIST, Fashion-MNIST, CIFAR-10), and we also demonstrate that it specifically tackles issues with multiple input modes. We also identify open problems when distilling agents trained in high dimensional environments such as Pong, Breakout, or Seaquest.