 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient and Interpretable Tabular Anomaly Detection
Paper and Code
Mar 03, 2022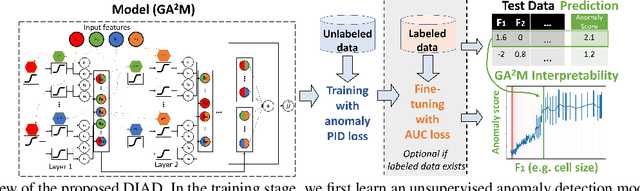
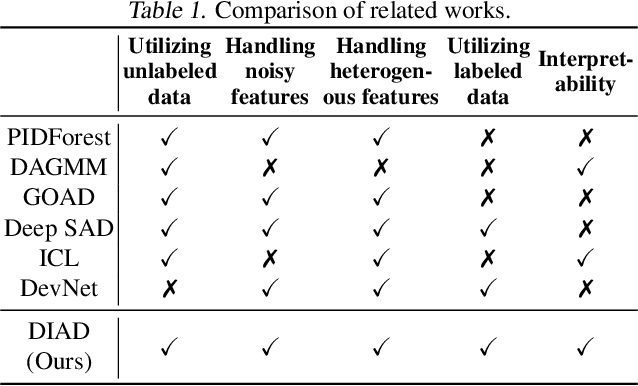
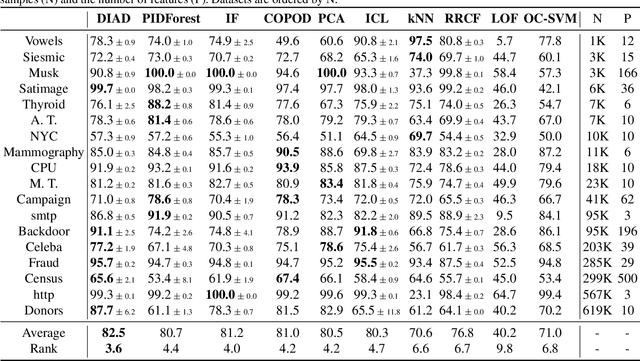
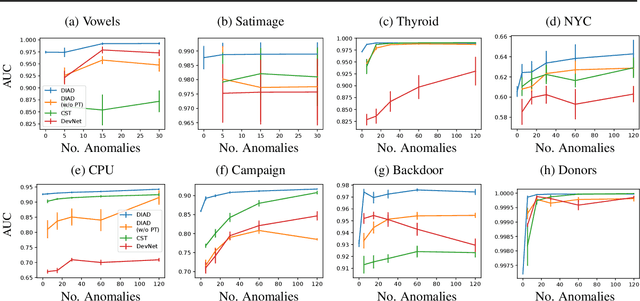
Anomaly detection (AD) plays an important role in numerous applications. We focus on two understudied aspects of AD that are critical for integration into real-world applications. First, most AD methods cannot incorporate labeled data that are often available in practice in small quantities and can be crucial to achieve high AD accuracy. Second, most AD methods are not interpretable, a bottleneck that prevents stakeholders from understanding the reason behind the anomalies. In this paper, we propose a novel AD framework that adapts a white-box model class, Generalized Additive Models, to detect anomalies using a partial identification objective which naturally handles noisy or heterogeneous features. In addition, the proposed framework, DIAD, can incorporate a small amount of labeled data to further boost anomaly detection performances in semi-supervised settings. We demonstrate the superiority of our framework compared to previous work in both unsupervised and semi-supervised settings using diverse tabular datasets. For example, under 5 labeled anomalies DIAD improves from 86.2\% to 89.4\% AUC by learning AD from unlabeled data. We also present insightful interpretations that explain why DIAD deems certain samples as anomalies.