 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Clinicians Want: Contextualizing Explainable Machine Learning for Clinical End Use
Paper and Code
May 13, 2019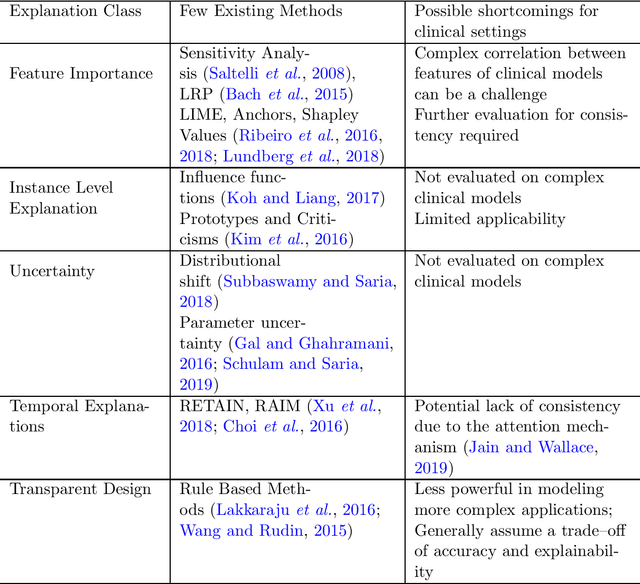
Translating machine learning (ML) models effectively to clinical practice requires establishing clinicians' trust. Explainability, or the ability of an ML model to justify its outcomes and assist clinicians in rationalizing the model prediction, has been generally understood to be critical to establishing trust. However, the field suffers from the lack of concrete definitions for usable explanations in different settings. To identify specific aspects of explainability that may catalyze building trust in ML models, we surveyed clinicians from two distinct acute care specialties (Intenstive Care Unit and Emergency Department). We use their feedback to characterize when explainability helps to improve clinicians' trust in ML models. We further identify the classes of explanations that clinicians identified as most relevant and crucial for effective translation to clinical practice. Finally, we discern concrete metrics for rigorous evaluation of clinical explainability methods. By integrating perceptions of explainability between clinicians and ML researchers we hope to facilitate the endorsement and broader adoption and sustained use of ML systems in healthcare.