 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Order Matters for Compositional Scene Understanding
Paper and Code
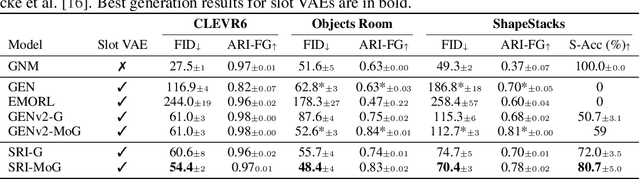
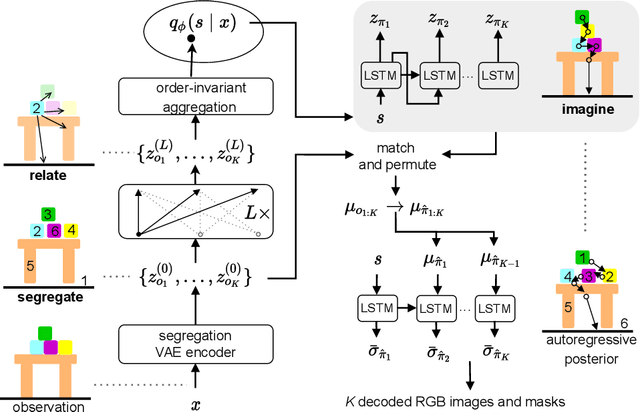


Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations ("slots") from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.