 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenNBV: Generalizable Next-Best-View Policy for Active 3D Reconstruction
Paper and Code
Feb 25, 2024
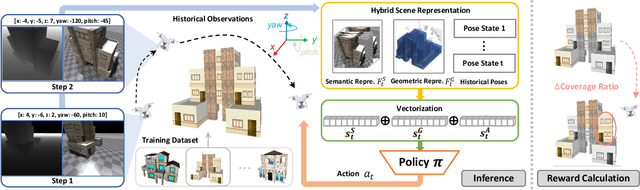


While recent advances in neural radiance field enable realistic digitization for large-scale scenes, the image-capturing process is still time-consuming and labor-intensive. Previous works attempt to automate this process using the Next-Best-View (NBV) policy for active 3D reconstruction. However, the existing NBV policies heavily rely on hand-crafted criteria, limited action space, or per-scene optimized representations. These constraints limit their cross-dataset generalizability. To overcome them, we propose GenNBV, an end-to-end generalizable NBV policy. Our policy adopts a reinforcement learning (RL)-based framework and extends typical limited action space to 5D free space. It empowers our agent drone to scan from any viewpoint, and even interact with unseen geometries during training. To boost the cross-dataset generalizability, we also propose a novel multi-source state embedding, including geometric, semantic, and action representations. We establish a benchmark using the Isaac Gym simulator with the Houses3K and OmniObject3D datasets to evaluate this NBV policy. Experiments demonstrate that our policy achieves a 98.26% and 97.12% coverage ratio on unseen building-scale objects from these datasets, respectively, outperforming prior solutions.