 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoPlanes: A Novel Representation for Better 3D-Awareness of GANs
Sep 27, 2023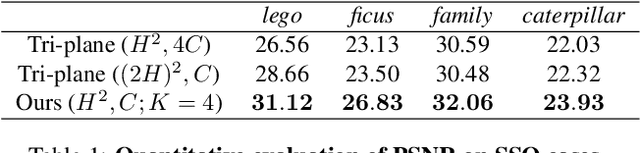
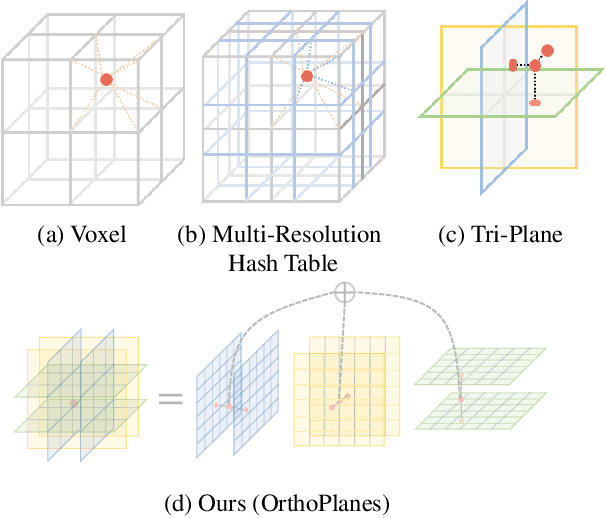
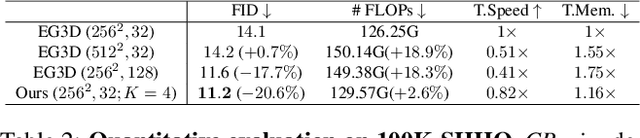

We present a new method for generating realistic and view-consistent images with fine geometry from 2D image collections. Our method proposes a hybrid explicit-implicit representation called \textbf{OrthoPlanes}, which encodes fine-grained 3D information in feature maps that can be efficiently generated by modifying 2D StyleGANs. Compared to previous representations, our method has better scalability and expressiveness with clear and explicit information. As a result, our method can handle more challenging view-angles and synthesize articulated objects with high spatial degree of freedom. Experiments demonstrate that our method achieves state-of-the-art results on FFHQ and SHHQ datasets, both quantitatively and qualitatively. Project page: \url{https://orthoplanes.github.io/}.
3DHumanGAN: Towards Photo-Realistic 3D-Aware Human Image Generation
Dec 14, 2022We present 3DHumanGAN, a 3D-aware generative adversarial network (GAN) that synthesizes images of full-body humans with consistent appearances under different view-angles and body-poses. To tackle the representational and computational challenges in synthesizing the articulated structure of human bodies, we propose a novel generator architecture in which a 2D convolutional backbone is modulated by a 3D pose mapping network. The 3D pose mapping network is formulated as a renderable implicit function conditioned on a posed 3D human mesh. This design has several merits: i) it allows us to harness the power of 2D GANs to generate photo-realistic images; ii) it generates consistent images under varying view-angles and specifiable poses; iii) the model can benefit from the 3D human prior. Our model is adversarially learned from a collection of web images needless of manual annotation.
MoCaNet: Motion Retargeting in-the-wild via Canonicalization Networks
Dec 21, 2021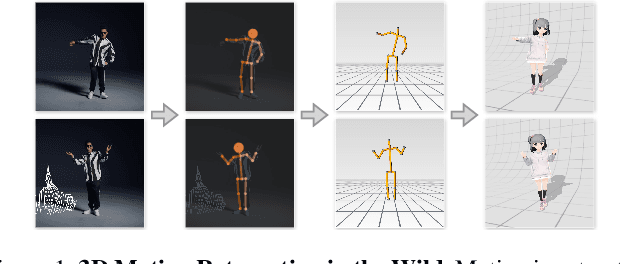

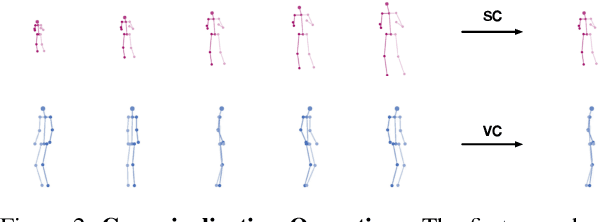

We present a novel framework that brings the 3D motion retargeting task from controlled environments to in-the-wild scenarios. In particular, our method is capable of retargeting body motion from a character in a 2D monocular video to a 3D character without using any motion capture system or 3D reconstruction procedure. It is designed to leverage massive online videos for unsupervised training, needless of 3D annotations or motion-body pairing information. The proposed method is built upon two novel canonicalization operations, structure canonicalization and view canonicalization. Trained with the canonicalization operations and the derived regularizations, our method learns to factorize a skeleton sequence into three independent semantic subspaces, i.e., motion, structure, and view angle. The disentangled representation enables motion retargeting from 2D to 3D with high precision. Our method achieves superior performance on motion transfer benchmarks with large body variations and challenging actions. Notably, the canonicalized skeleton sequence could serve as a disentangled and interpretable representation of human motion that benefits action analysis and motion retrieval.
TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting
Apr 01, 2020

We present a lightweight video motion retargeting approach TransMoMo that is capable of transferring motion of a person in a source video realistically to another video of a target person. Without using any paired data for supervision, the proposed method can be trained in an unsupervised manner by exploiting invariance properties of three orthogonal factors of variation including motion, structure, and view-angle. Specifically, with loss functions carefully derived based on invariance, we train an auto-encoder to disentangle the latent representations of such factors given the source and target video clips. This allows us to selectively transfer motion extracted from the source video seamlessly to the target video in spite of structural and view-angle disparities between the source and the target. The relaxed assumption of paired data allows our method to be trained on a vast amount of videos needless of manual annotation of source-target pairing, leading to improved robustness against large structural variations and extreme motion in videos. We demonstrate the effectiveness of our method over the state-of-the-art methods. Code, model and data are publicly available on our project page (https://yzhq97.github.io/transmomo).
Multi-modal Learning with Prior Visual Relation Reasoning
Dec 23, 2018
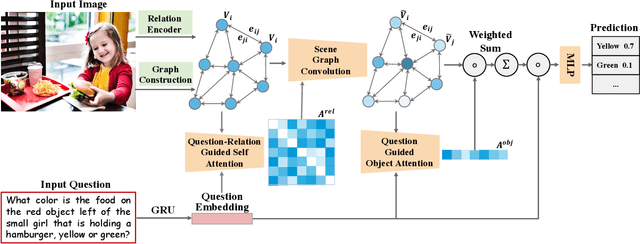
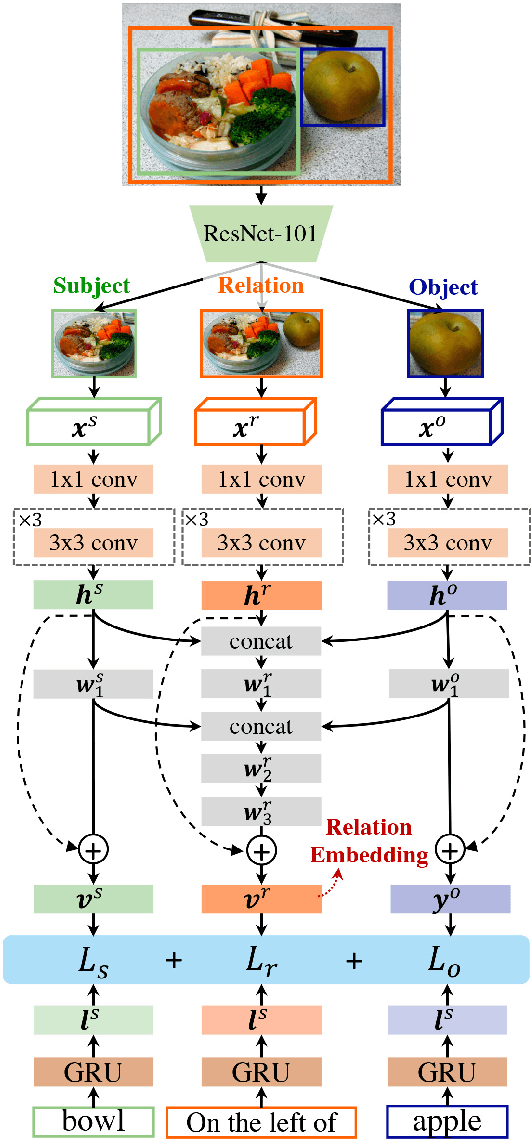
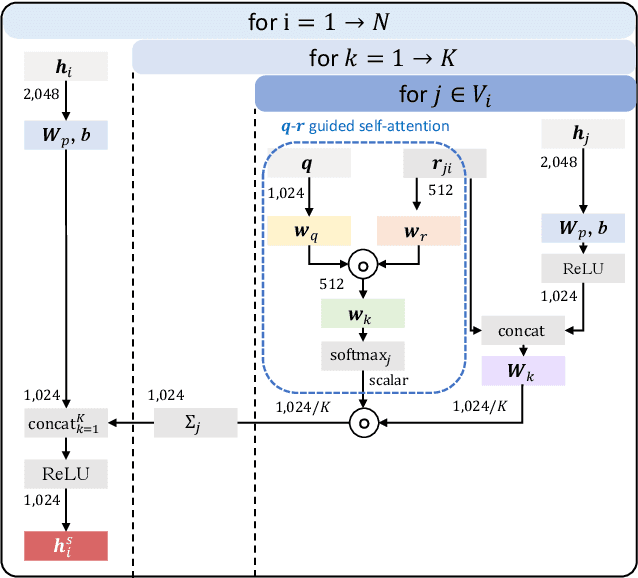
Visual relation reasoning is a central component in recent cross-modal analysis tasks, which aims at reasoning about the visual relationships between objects and their properties. These relationships convey rich semantics and help to enhance the visual representation for improving cross-modal analysis. Previous works have succeeded in designing strategies for modeling latent relations or rigid-categorized relations and achieving the lift of performance. However, this kind of methods leave out the ambiguity inherent in the relations because of the diverse relational semantics of different visual appearances. In this work, we explore to model relations by contextual-sensitive embeddings based on human priori knowledge. We novelly propose a plug-and-play relation reasoning module injected with the relation embeddings to enhance image encoder. Specifically, we design upgraded Graph Convolutional Networks (GCN) to utilize the information of relation embeddings and relation directionality between objects for generating relation-aware image representations. We demonstrate the effectiveness of the relation reasoning module by applying it to both Visual Question Answering (VQA) and Cross-Modal Information Retrieval (CMIR) tasks. Extensive experiments are conducted on VQA 2.0 and CMPlaces datasets and superior performance is reported when comparing with state-of-the-art work.