 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming the Latent Space of StyleGAN for Real Face Editing
May 29, 2021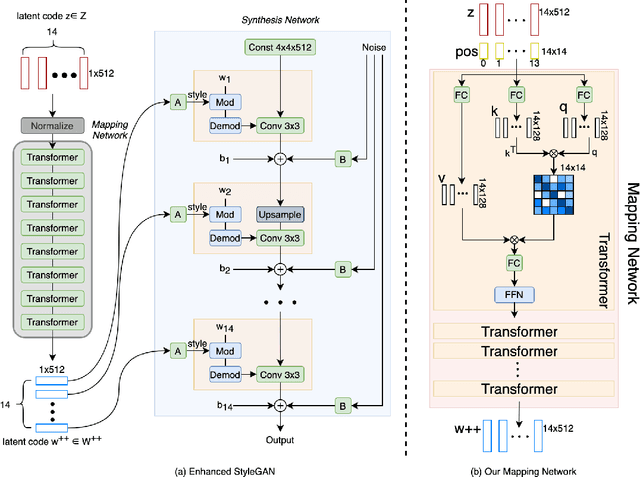

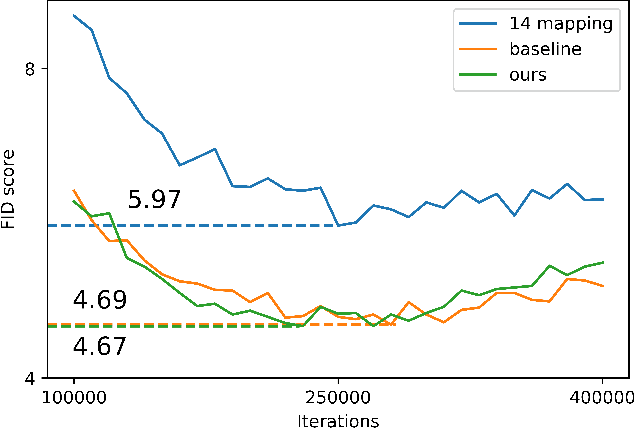

Despite recent advances in semantic manipulation using StyleGAN, semantic editing of real faces remains challenging. The gap between the $W$ space and the $W$+ space demands an undesirable trade-off between reconstruction quality and editing quality. To solve this problem, we propose to expand the latent space by replacing fully-connected layers in the StyleGAN's mapping network with attention-based transformers. This simple and effective technique integrates the aforementioned two spaces and transforms them into one new latent space called $W$++. Our modified StyleGAN maintains the state-of-the-art generation quality of the original StyleGAN with moderately better diversity. But more importantly, the proposed $W$++ space achieves superior performance in both reconstruction quality and editing quality. Despite these significant advantages, our $W$++ space supports existing inversion algorithms and editing methods with only negligible modifications thanks to its structural similarity with the $W/W$+ space. Extensive experiments on the FFHQ dataset prove that our proposed $W$++ space is evidently more preferable than the previous $W/W$+ space for real face editing. The code is publicly available for research purposes at https://github.com/AnonSubm2021/TransStyleGAN.
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Feb 24, 2020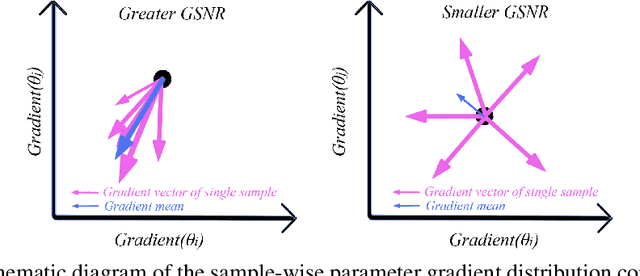
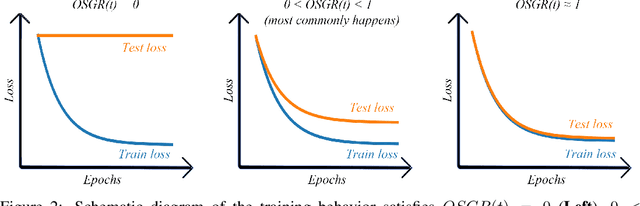

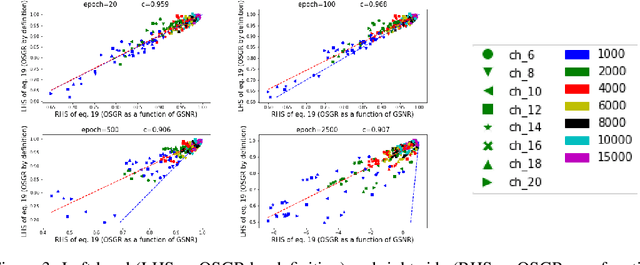
As deep neural networks (DNNs) achieve tremendous success across many application domains, researchers tried to explore in many aspects on why they generalize well. In this paper, we provide a novel perspective on these issues using the gradient signal to noise ratio (GSNR) of parameters during training process of DNNs. The GSNR of a parameter is defined as the ratio between its gradient's squared mean and variance, over the data distribution. Based on several approximations, we establish a quantitative relationship between model parameters' GSNR and the generalization gap. This relationship indicates that larger GSNR during training process leads to better generalization performance. Moreover, we show that, different from that of shallow models (e.g. logistic regression, support vector machines), the gradient descent optimization dynamics of DNNs naturally produces large GSNR during training, which is probably the key to DNNs' remarkable generalization ability.