 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models on Financial Report Summarization: An Empirical Study
Nov 11, 2024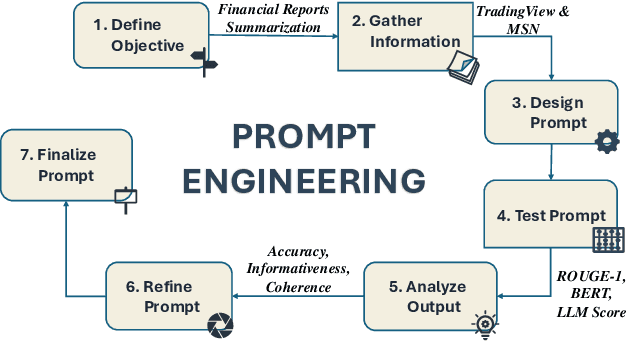


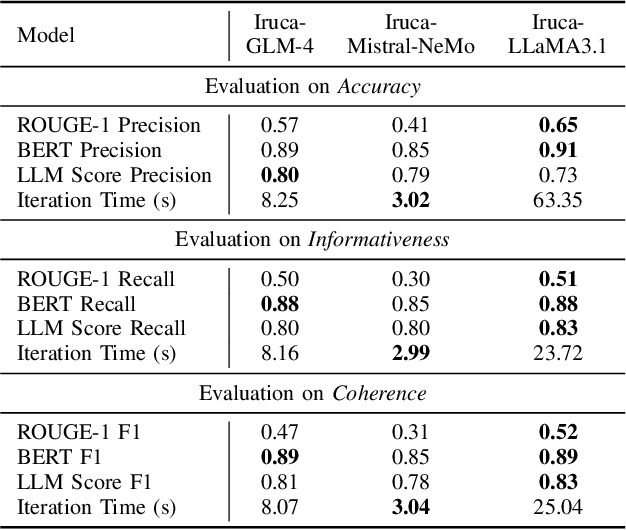
In recent years, Large Language Models (LLMs) have demonstrated remarkable versatility across various applications, including natural language understanding, domain-specific knowledge tasks, etc. However, applying LLMs to complex, high-stakes domains like finance requires rigorous evaluation to ensure reliability, accuracy, and compliance with industry standards. To address this need, we conduct a comprehensive and comparative study on three state-of-the-art LLMs, GLM-4, Mistral-NeMo, and LLaMA3.1, focusing on their effectiveness in generating automated financial reports. Our primary motivation is to explore how these models can be harnessed within finance, a field demanding precision, contextual relevance, and robustness against erroneous or misleading information. By examining each model's capabilities, we aim to provide an insightful assessment of their strengths and limitations. Our paper offers benchmarks for financial report analysis, encompassing proposed metrics such as ROUGE-1, BERT Score, and LLM Score. We introduce an innovative evaluation framework that integrates both quantitative metrics (e.g., precision, recall) and qualitative analyses (e.g., contextual fit, consistency) to provide a holistic view of each model's output quality. Additionally, we make our financial dataset publicly available, inviting researchers and practitioners to leverage, scrutinize, and enhance our findings through broader community engagement and collaborative improvement. Our dataset is available on huggingface.