 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Deepfake Detection Based on a Combination of F0 Information and Real Plus Imaginary Spectrogram Features
Aug 02, 2022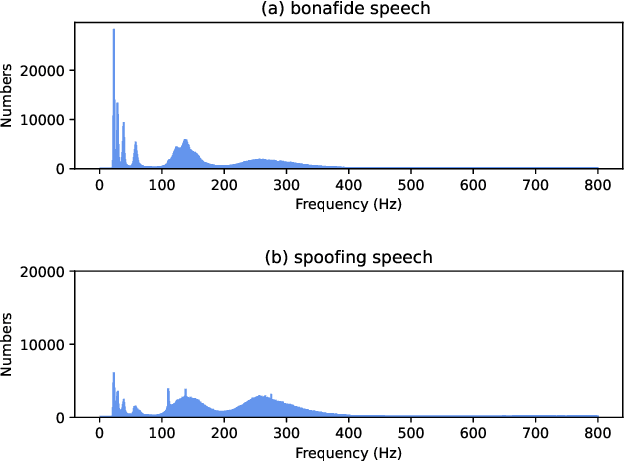


Recently, pioneer research works have proposed a large number of acoustic features (log power spectrogram, linear frequency cepstral coefficients, constant Q cepstral coefficients, etc.) for audio deepfake detection, obtaining good performance, and showing that different subbands have different contributions to audio deepfake detection. However, this lacks an explanation of the specific information in the subband, and these features also lose information such as phase. Inspired by the mechanism of synthetic speech, the fundamental frequency (F0) information is used to improve the quality of synthetic speech, while the F0 of synthetic speech is still too average, which differs significantly from that of real speech. It is expected that F0 can be used as important information to discriminate between bonafide and fake speech, while this information cannot be used directly due to the irregular distribution of F0. Insteadly, the frequency band containing most of F0 is selected as the input feature. Meanwhile, to make full use of the phase and full-band information, we also propose to use real and imaginary spectrogram features as complementary input features and model the disjoint subbands separately. Finally, the results of F0, real and imaginary spectrogram features are fused. Experimental results on the ASVspoof 2019 LA dataset show that our proposed system is very effective for the audio deepfake detection task, achieving an equivalent error rate (EER) of 0.43%, which surpasses almost all systems.