 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCCSP: A Scalable Framework for Enhancing Time Series Forecasting with Time-Lagged Cross-Correlations
Aug 09, 2025



Time series forecasting is critical across various domains, such as weather, finance and real estate forecasting, as accurate forecasts support informed decision-making and risk mitigation. While recent deep learning models have improved predictive capabilities, they often overlook time-lagged cross-correlations between related sequences, which are crucial for capturing complex temporal relationships. To address this, we propose the Time-Lagged Cross-Correlations-based Sequence Prediction framework (TLCCSP), which enhances forecasting accuracy by effectively integrating time-lagged cross-correlated sequences. TLCCSP employs the Sequence Shifted Dynamic Time Warping (SSDTW) algorithm to capture lagged correlations and a contrastive learning-based encoder to efficiently approximate SSDTW distances. Experimental results on weather, finance and real estate time series datasets demonstrate the effectiveness of our framework. On the weather dataset, SSDTW reduces mean squared error (MSE) by 16.01% compared with single-sequence methods, while the contrastive learning encoder (CLE) further decreases MSE by 17.88%. On the stock dataset, SSDTW achieves a 9.95% MSE reduction, and CLE reduces it by 6.13%. For the real estate dataset, SSDTW and CLE reduce MSE by 21.29% and 8.62%, respectively. Additionally, the contrastive learning approach decreases SSDTW computational time by approximately 99%, ensuring scalability and real-time applicability across multiple time series forecasting tasks.
Demonstration Selection for In-Context Learning via Reinforcement Learning
Dec 05, 2024Diversity in demonstration selection is crucial for enhancing model generalization, as it enables a broader coverage of structures and concepts. However, constructing an appropriate set of demonstrations has remained a focal point of research. This paper presents the Relevance-Diversity Enhanced Selection (RDES), an innovative approach that leverages reinforcement learning to optimize the selection of diverse reference demonstrations for text classification tasks using Large Language Models (LLMs), especially in few-shot prompting scenarios. RDES employs a Q-learning framework to dynamically identify demonstrations that maximize both diversity and relevance to the classification objective by calculating a diversity score based on label distribution among selected demonstrations. This method ensures a balanced representation of reference data, leading to improved classification accuracy. Through extensive experiments on four benchmark datasets and involving 12 closed-source and open-source LLMs, we demonstrate that RDES significantly enhances classification accuracy compared to ten established baselines. Furthermore, we investigate the incorporation of Chain-of-Thought (CoT) reasoning in the reasoning process, which further enhances the model's predictive performance. The results underscore the potential of reinforcement learning to facilitate adaptive demonstration selection and deepen the understanding of classification challenges.
Enhancing Text Annotation through Rationale-Driven Collaborative Few-Shot Prompting
Sep 15, 2024

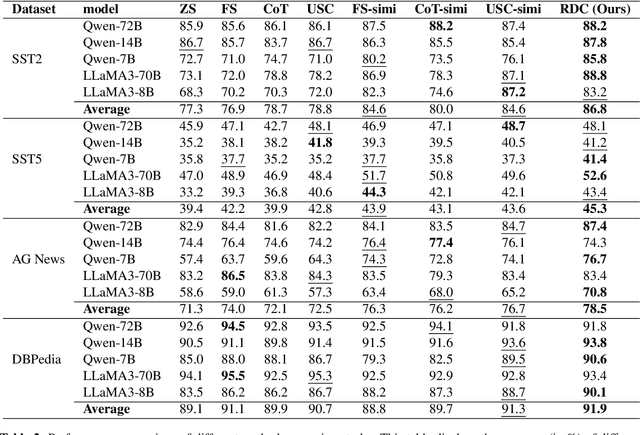
The traditional data annotation process is often labor-intensive, time-consuming, and susceptible to human bias, which complicates the management of increasingly complex datasets. This study explores the potential of large language models (LLMs) as automated data annotators to improve efficiency and consistency in annotation tasks. By employing rationale-driven collaborative few-shot prompting techniques, we aim to improve the performance of LLMs in text annotation. We conduct a rigorous evaluation of six LLMs across four benchmark datasets, comparing seven distinct methodologies. Our results demonstrate that collaborative methods consistently outperform traditional few-shot techniques and other baseline approaches, particularly in complex annotation tasks. Our work provides valuable insights and a robust framework for leveraging collaborative learning methods to tackle challenging text annotation tasks.