 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Search, But Scan: Benchmarking MLLMs on Scan-Oriented Academic Paper Reasoning
Mar 27, 2026With the rapid progress of multimodal large language models (MLLMs), AI already performs well at literature retrieval and certain reasoning tasks, serving as a capable assistant to human researchers, yet it remains far from autonomous research. The fundamental reason is that current work on academic paper reasoning is largely confined to a search-oriented paradigm centered on pre-specified targets, with reasoning grounded in relevance retrieval, which struggles to support researcher-style full-document understanding, reasoning, and verification. To bridge this gap, we propose \textbf{ScholScan}, a new benchmark for academic paper reasoning. ScholScan introduces a scan-oriented task setting that asks models to read and cross-check entire papers like human researchers, scanning the document to identify consistency issues. The benchmark comprises 1,800 carefully annotated questions drawn from nine error categories across 13 natural-science domains and 715 papers, and provides detailed annotations for evidence localization and reasoning traces, together with a unified evaluation protocol. We assessed 15 models across 24 input configurations and conducted a fine-grained analysis of MLLM capabilities for all error categories. Across the board, retrieval-augmented generation (RAG) methods yield no significant improvements, revealing systematic deficiencies of current MLLMs on scan-oriented tasks and underscoring the challenge posed by ScholScan. We expect ScholScan to be the leading and representative work of the scan-oriented task paradigm.
Noisy Node Classification by Bi-level Optimization based Multi-teacher Distillation
Apr 27, 2024



Previous graph neural networks (GNNs) usually assume that the graph data is with clean labels for representation learning, but it is not true in real applications. In this paper, we propose a new multi-teacher distillation method based on bi-level optimization (namely BO-NNC), to conduct noisy node classification on the graph data. Specifically, we first employ multiple self-supervised learning methods to train diverse teacher models, and then aggregate their predictions through a teacher weight matrix. Furthermore, we design a new bi-level optimization strategy to dynamically adjust the teacher weight matrix based on the training progress of the student model. Finally, we design a label improvement module to improve the label quality. Extensive experimental results on real datasets show that our method achieves the best results compared to state-of-the-art methods.
Research on facial expression recognition based on Multimodal data fusion and neural network
Sep 26, 2021
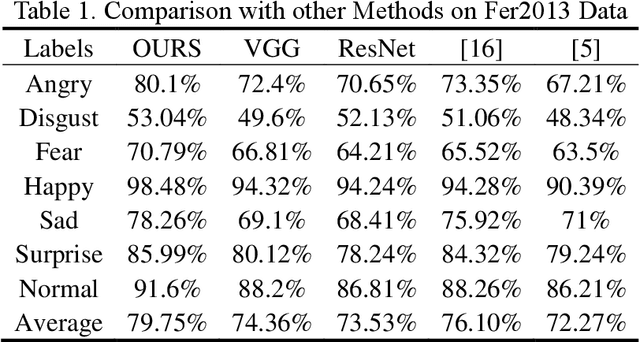
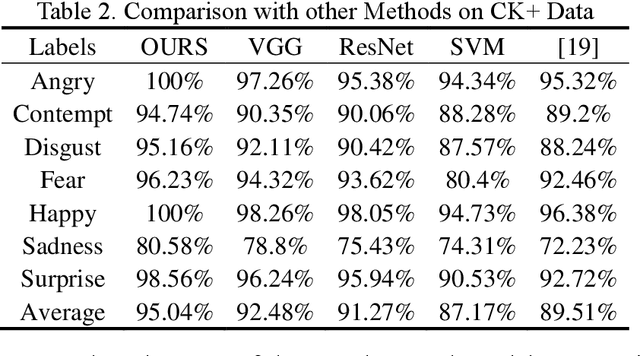
Facial expression recognition is a challenging task when neural network is applied to pattern recognition. Most of the current recognition research is based on single source facial data, which generally has the disadvantages of low accuracy and low robustness. In this paper, a neural network algorithm of facial expression recognition based on multimodal data fusion is proposed. The algorithm is based on the multimodal data, and it takes the facial image, the histogram of oriented gradient of the image and the facial landmarks as the input, and establishes CNN, LNN and HNN three sub neural networks to extract data features, using multimodal data feature fusion mechanism to improve the accuracy of facial expression recognition. Experimental results show that, benefiting by the complementarity of multimodal data, the algorithm has a great improvement in accuracy, robustness and detection speed compared with the traditional facial expression recognition algorithm. Especially in the case of partial occlusion, illumination and head posture transformation, the algorithm also shows a high confidence.