 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild
Paper and Code

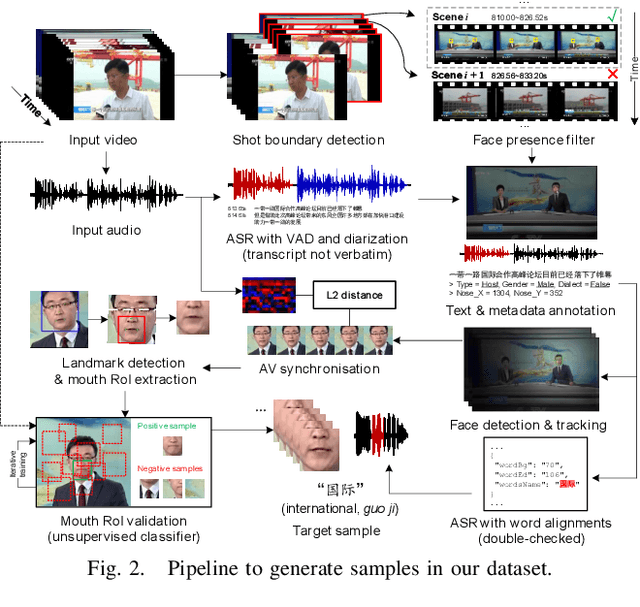
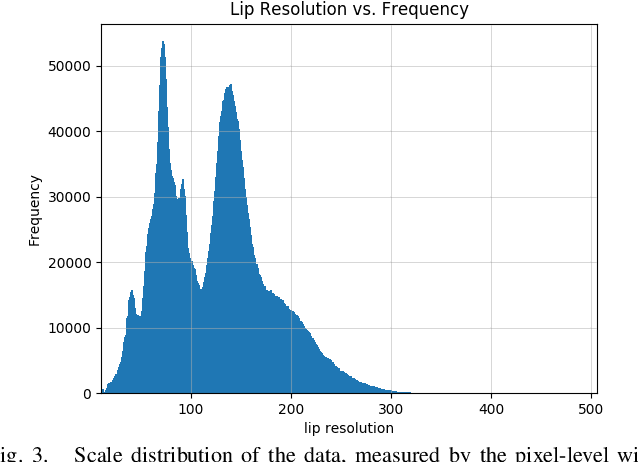
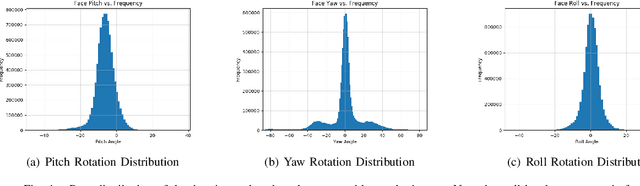
Large-scale datasets have successively proven their fundamental importance in several research fields, especially for early progress in some emerging topics. In this paper, we focus on the problem of visual speech recognition, also known as lipreading, which has received an increasing interest in recent years. We present a naturally-distributed large-scale benchmark for lip reading in the wild, named LRW-1000, which contains 1000 classes with about 745,187 samples from more than 2000 individual speakers. Each class corresponds to the syllables of a Mandarin word which is composed of one or several Chinese characters. To the best of our knowledge, it is the largest word-level lipreading dataset and also the only public large-scale Mandarin lipreading dataset. This dataset aims at covering a "natural" variability over different speech modes and imaging conditions to incorporate challenges encountered in practical applications. This benchmark shows a large variation over several aspects, including the number of samples in each class, resolution of videos, lighting conditions, and speakers' attributes such as pose, age, gender, and make-up. Besides a detailed description of the dataset and its collection pipeline, we evaluate the popular lipreading methods and perform a thorough analysis of the results from several aspects. The results demonstrate the consistency and challenges of our dataset, which may open up some new promising directions for future work. The dataset and corresponding codes will be public for academic research use.