 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Feature Pyramid Attention Module for Robust Visual Speech Recognition
Paper and Code
Oct 17, 2018
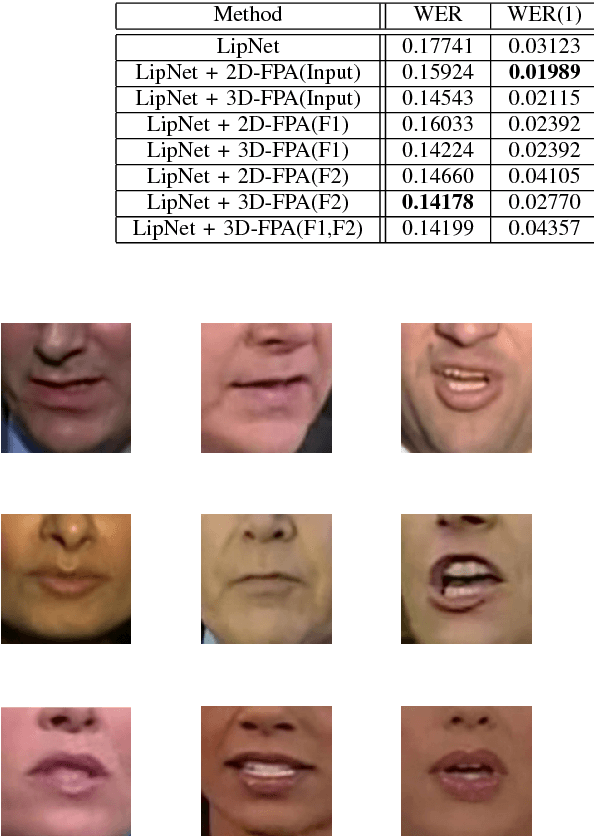


Visual speech recognition is the task to decode the speech content from a video based on visual information, especially the movements of lips. It is also referenced as lipreading. Motivated by two problems existing in lipreading, words with similar pronunciation and the variation of word duration, we propose a novel 3D Feature Pyramid Attention (3D-FPA) module to jointly improve the representation power of features in both the spatial and temporal domains. Specifically, the input features are downsampled for 3 times in both the spatial and temporal dimensions to construct spatiotemporal feature pyramids. Then high-level features are upsampled and combined with low-level features, finally generating a pixel-level soft attention mask to be multiplied with the input features.It enhances the discriminative power of features and exploits the temporal multi-scale information while decoding the visual speeches. Also, this module provides a new method to construct and utilize temporal pyramid structures in video analysis tasks. The field of temporal featrue pyramids are still under exploring compared to the plentiful works on spatial feature pyramids for image analysis tasks. To validate the effectiveness and adaptability of our proposed module, we embed the module in a sentence-level lipreading model, LipNet, with the result of 3.6% absolute decrease in word error rate, and a word-level model, with the result of 1.4% absolute improvement in accuracy.