 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixLens: A Novel Framework for Disentangled Evaluation in Diffusion-Based Image Editing with Object Detection + SAM
Paper and Code
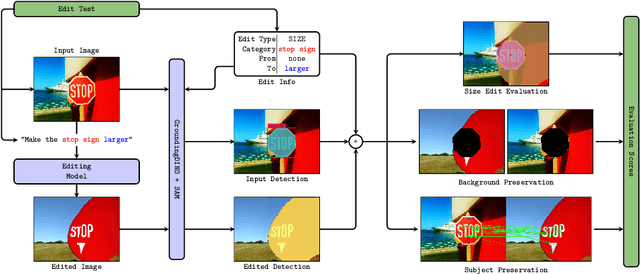


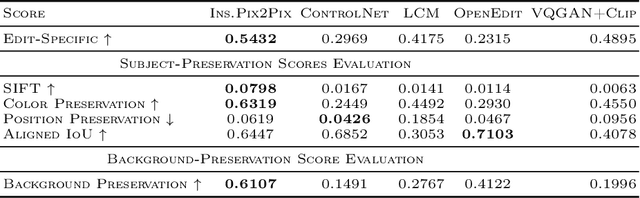
Evaluating diffusion-based image-editing models is a crucial task in the field of Generative AI. Specifically, it is imperative to assess their capacity to execute diverse editing tasks while preserving the image content and realism. While recent developments in generative models have opened up previously unheard-of possibilities for image editing, conducting a thorough evaluation of these models remains a challenging and open task. The absence of a standardized evaluation benchmark, primarily due to the inherent need for a post-edit reference image for evaluation, further complicates this issue. Currently, evaluations often rely on established models such as CLIP or require human intervention for a comprehensive understanding of the performance of these image editing models. Our benchmark, PixLens, provides a comprehensive evaluation of both edit quality and latent representation disentanglement, contributing to the advancement and refinement of existing methodologies in the field.