 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMammoDL: Mammographic Breast Density Estimation using Federated Learning
Jun 11, 2022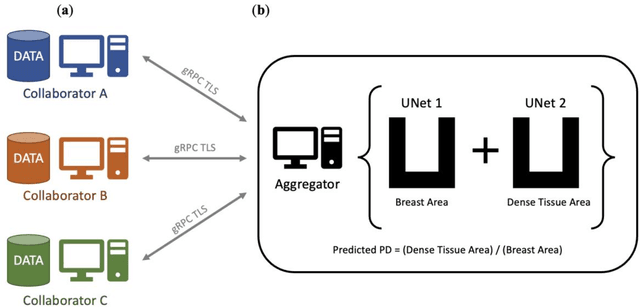


Assessing breast cancer risk from imaging remains a subjective process, in which radiologists employ computer aided detection (CAD) systems or qualitative visual assessment to estimate breast percent density (PD). More advanced machine learning (ML) models have become the most promising way to quantify breast cancer risk for early, accurate, and equitable diagnoses, but training such models in medical research is often restricted to small, single-institution data. Since patient demographics and imaging characteristics may vary considerably across imaging sites, models trained on single-institution data tend not to generalize well. In response to this problem, MammoDL is proposed, an open-source software tool that leverages UNet architecture to accurately estimate breast PD and complexity from digital mammography (DM). With the Open Federated Learning (OpenFL) library, this solution enables secure training on datasets across multiple institutions. MammoDL is a leaner, more flexible model than its predecessors, boasting improved generalization due to federation-enabled training on larger, more representative datasets.
Deep-LIBRA: Artificial intelligence method for robust quantification of breast density with independent validation in breast cancer risk assessment
Nov 17, 2020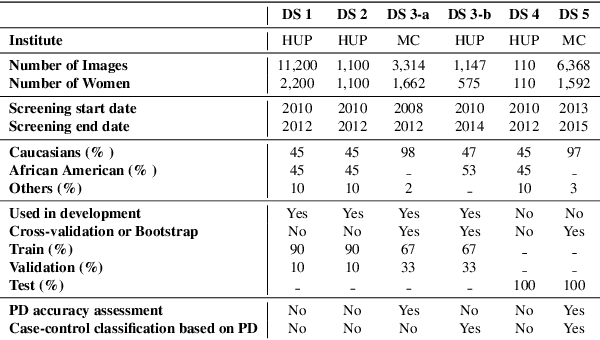
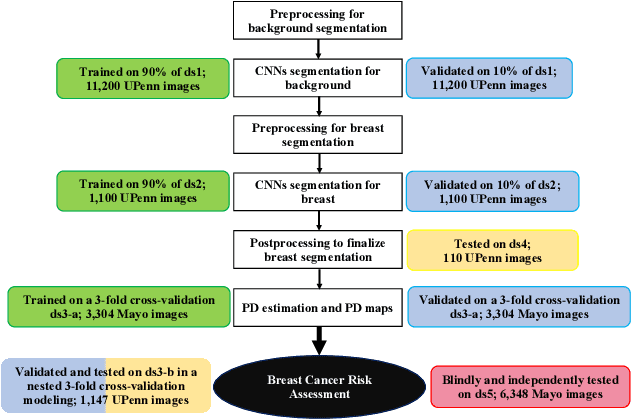
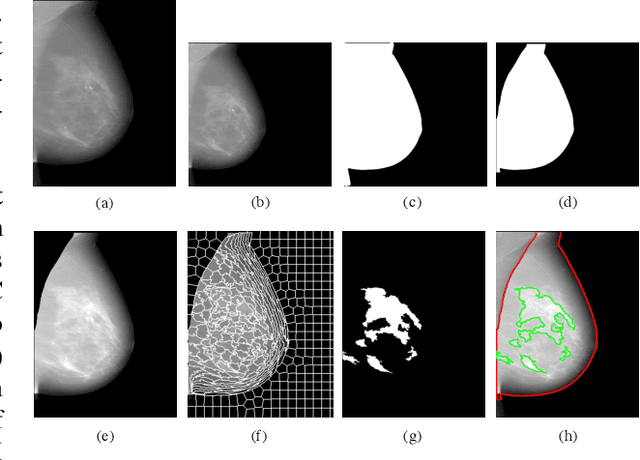
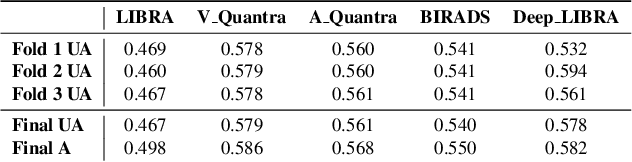
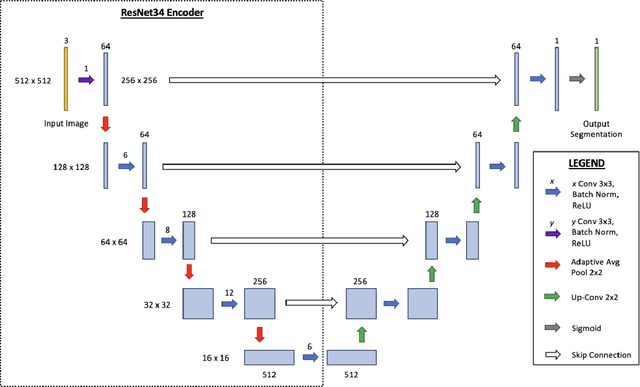
Breast density is an important risk factor for breast cancer that also affects the specificity and sensitivity of screening mammography. Current federal legislation mandates reporting of breast density for all women undergoing breast screening. Clinically, breast density is assessed visually using the American College of Radiology Breast Imaging Reporting And Data System (BI-RADS) scale. Here, we introduce an artificial intelligence (AI) method to estimate breast percentage density (PD) from digital mammograms. Our method leverages deep learning (DL) using two convolutional neural network architectures to accurately segment the breast area. A machine-learning algorithm combining superpixel generation, texture feature analysis, and support vector machine is then applied to differentiate dense from non-dense tissue regions, from which PD is estimated. Our method has been trained and validated on a multi-ethnic, multi-institutional dataset of 15,661 images (4,437 women), and then tested on an independent dataset of 6,368 digital mammograms (1,702 women; cases=414) for both PD estimation and discrimination of breast cancer. On the independent dataset, PD estimates from Deep-LIBRA and an expert reader were strongly correlated (Spearman correlation coefficient = 0.90). Moreover, Deep-LIBRA yielded a higher breast cancer discrimination performance (area under the ROC curve, AUC = 0.611 [95% confidence interval (CI): 0.583, 0.639]) compared to four other widely-used research and commercial PD assessment methods (AUCs = 0.528 to 0.588). Our results suggest a strong agreement of PD estimates between Deep-LIBRA and gold-standard assessment by an expert reader, as well as improved performance in breast cancer risk assessment over state-of-the-art open-source and commercial methods.