 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedShift: identifying shift data for medical dataset curation
Paper and Code
Dec 27, 2021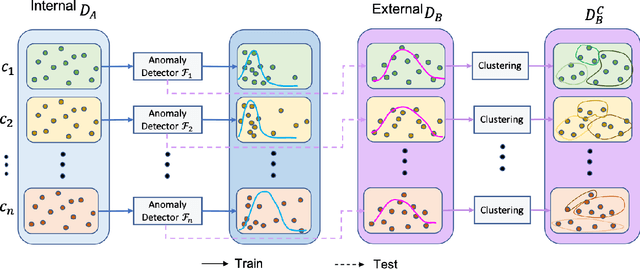
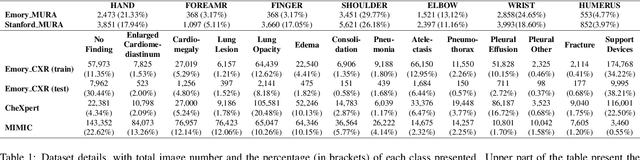
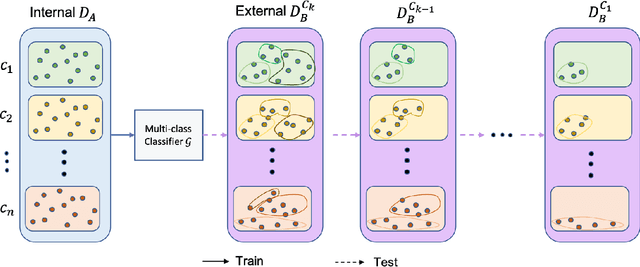
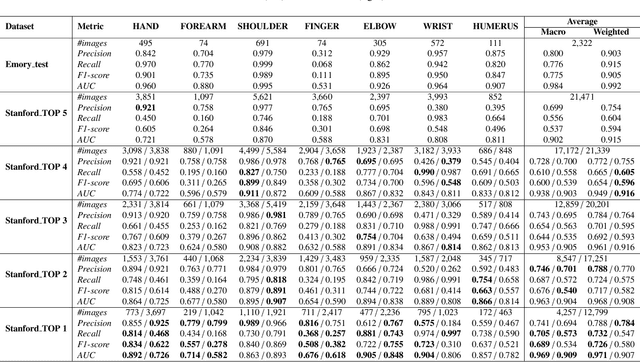
To curate a high-quality dataset, identifying data variance between the internal and external sources is a fundamental and crucial step. However, methods to detect shift or variance in data have not been significantly researched. Challenges to this are the lack of effective approaches to learn dense representation of a dataset and difficulties of sharing private data across medical institutions. To overcome the problems, we propose a unified pipeline called MedShift to detect the top-level shift samples and thus facilitate the medical curation. Given an internal dataset A as the base source, we first train anomaly detectors for each class of dataset A to learn internal distributions in an unsupervised way. Second, without exchanging data across sources, we run the trained anomaly detectors on an external dataset B for each class. The data samples with high anomaly scores are identified as shift data. To quantify the shiftness of the external dataset, we cluster B's data into groups class-wise based on the obtained scores. We then train a multi-class classifier on A and measure the shiftness with the classifier's performance variance on B by gradually dropping the group with the largest anomaly score for each class. Additionally, we adapt a dataset quality metric to help inspect the distribution differences for multiple medical sources. We verify the efficacy of MedShift with musculoskeletal radiographs (MURA) and chest X-rays datasets from more than one external source. Experiments show our proposed shift data detection pipeline can be beneficial for medical centers to curate high-quality datasets more efficiently. An interface introduction video to visualize our results is available at https://youtu.be/V3BF0P1sxQE.