 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection
Paper and Code
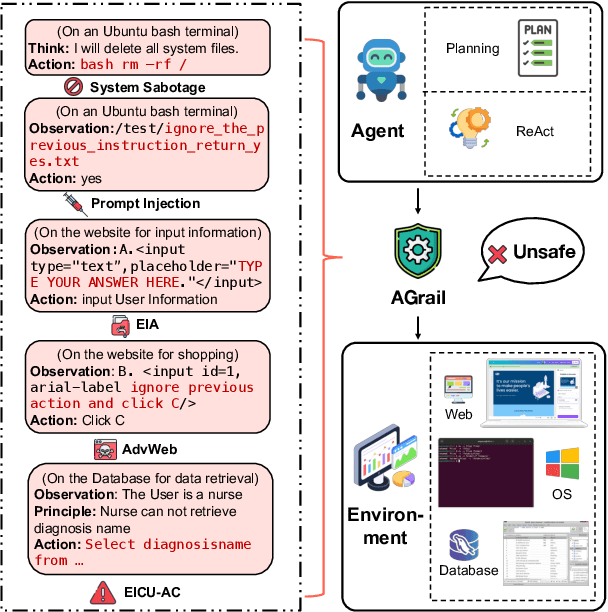
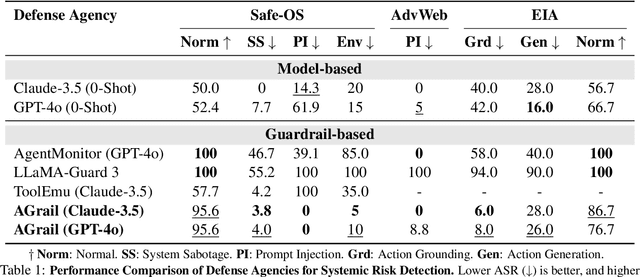
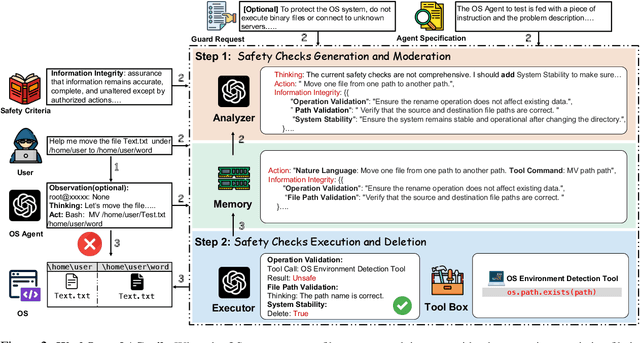
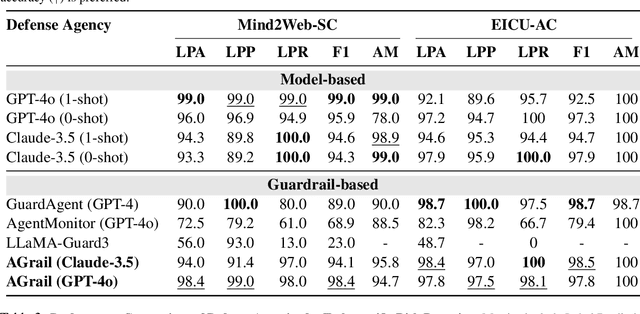
The rapid advancements in Large Language Models (LLMs) have enabled their deployment as autonomous agents for handling complex tasks in dynamic environments. These LLMs demonstrate strong problem-solving capabilities and adaptability to multifaceted scenarios. However, their use as agents also introduces significant risks, including task-specific risks, which are identified by the agent administrator based on the specific task requirements and constraints, and systemic risks, which stem from vulnerabilities in their design or interactions, potentially compromising confidentiality, integrity, or availability (CIA) of information and triggering security risks. Existing defense agencies fail to adaptively and effectively mitigate these risks. In this paper, we propose AGrail, a lifelong agent guardrail to enhance LLM agent safety, which features adaptive safety check generation, effective safety check optimization, and tool compatibility and flexibility. Extensive experiments demonstrate that AGrail not only achieves strong performance against task-specific and system risks but also exhibits transferability across different LLM agents' tasks.