 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetalearning with Very Few Samples Per Task
Paper and Code
Dec 21, 2023
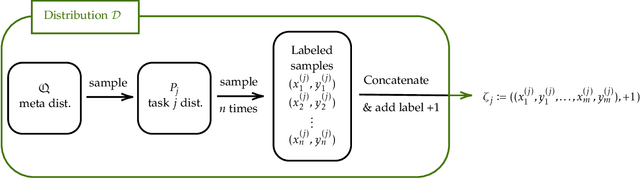
Metalearning and multitask learning are two frameworks for solving a group of related learning tasks more efficiently than we could hope to solve each of the individual tasks on their own. In multitask learning, we are given a fixed set of related learning tasks and need to output one accurate model per task, whereas in metalearning we are given tasks that are drawn i.i.d. from a metadistribution and need to output some common information that can be easily specialized to new, previously unseen tasks from the metadistribution. In this work, we consider a binary classification setting where tasks are related by a shared representation, that is, every task $P$ of interest can be solved by a classifier of the form $f_{P} \circ h$ where $h \in H$ is a map from features to some representation space that is shared across tasks, and $f_{P} \in F$ is a task-specific classifier from the representation space to labels. The main question we ask in this work is how much data do we need to metalearn a good representation? Here, the amount of data is measured in terms of both the number of tasks $t$ that we need to see and the number of samples $n$ per task. We focus on the regime where the number of samples per task is extremely small. Our main result shows that, in a distribution-free setting where the feature vectors are in $\mathbb{R}^d$, the representation is a linear map from $\mathbb{R}^d \to \mathbb{R}^k$, and the task-specific classifiers are halfspaces in $\mathbb{R}^k$, we can metalearn a representation with error $\varepsilon$ using just $n = k+2$ samples per task, and $d \cdot (1/\varepsilon)^{O(k)}$ tasks. Learning with so few samples per task is remarkable because metalearning would be impossible with $k+1$ samples per task, and because we cannot even hope to learn an accurate task-specific classifier with just $k+2$ samples per task.