 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Paper and Code
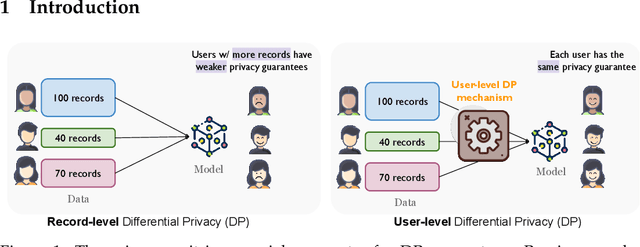
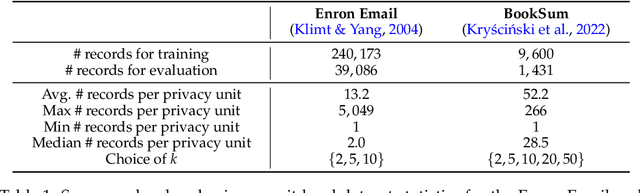

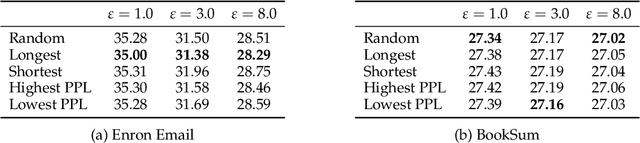
Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are `almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.