 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025

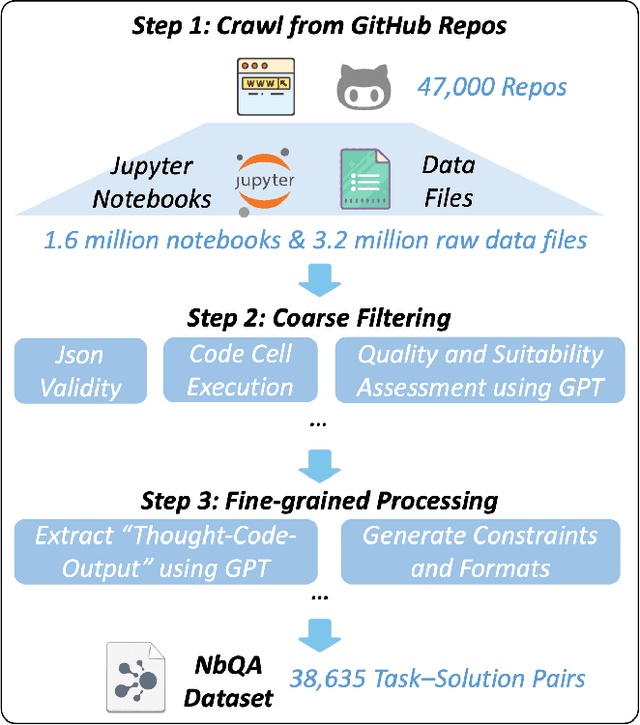
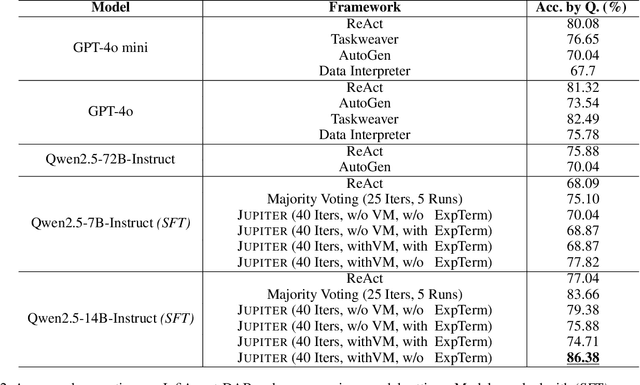
Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
Helmsman of the Masses? Evaluate the Opinion Leadership of Large Language Models in the Werewolf Game
Apr 02, 2024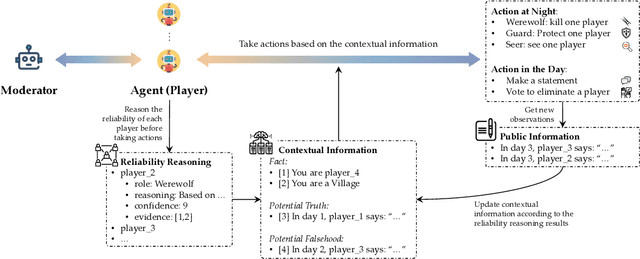
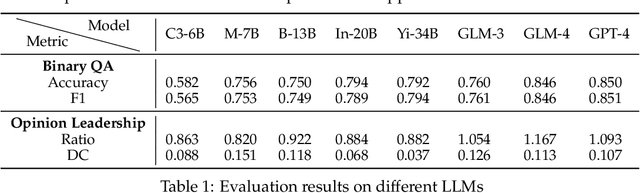

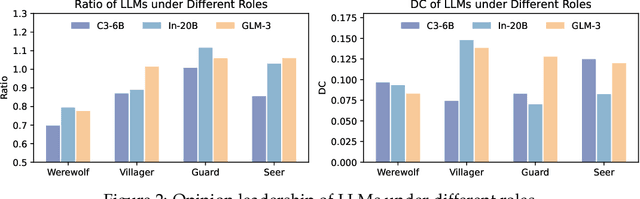
Large language models (LLMs) have exhibited memorable strategic behaviors in social deductive games. However, the significance of opinion leadership exhibited by LLM-based agents has been overlooked, which is crucial for practical applications in multi-agent and human-AI interaction settings. Opinion leaders are individuals who have a noticeable impact on the beliefs and behaviors of others within a social group. In this work, we employ the Werewolf game as a simulation platform to assess the opinion leadership of LLMs. The game features the role of the Sheriff, tasked with summarizing arguments and recommending decision options, and therefore serves as a credible proxy for an opinion leader. We develop a framework integrating the Sheriff role and devise two novel metrics for evaluation based on the critical characteristics of opinion leaders. The first metric measures the reliability of the opinion leader, and the second assesses the influence of the opinion leader on other players' decisions. We conduct extensive experiments to evaluate LLMs of different scales. In addition, we collect a Werewolf question-answering dataset (WWQA) to assess and enhance LLM's grasp of the game rules, and we also incorporate human participants for further analysis. The results suggest that the Werewolf game is a suitable test bed to evaluate the opinion leadership of LLMs and few LLMs possess the capacity for opinion leadership.