 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Density-Peaks Clustering via Matrix Computations on MPI Parallelization System
Jun 18, 2024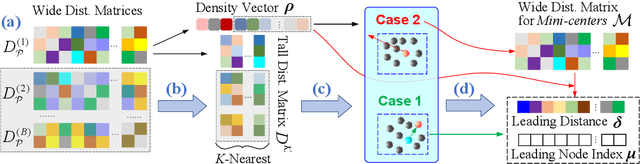



Density peaks clustering (DP) has the ability of detecting clusters of arbitrary shape and clustering non-Euclidean space data, but its quadratic complexity in both computing and storage makes it difficult to scale for big data. Various approaches have been proposed in this regard, including MapReduce based distribution computing, multi-core parallelism, presentation transformation (e.g., kd-tree, Z-value), granular computing, and so forth. However, most of these existing methods face two limitations. One is their target datasets are mostly constrained to be in Euclidian space, the other is they emphasize only on local neighbors while ignoring global data distribution due to restriction to cut-off kernel when computing density. To address the two issues, we present a faithful and parallel DP method that makes use of two types of vector-like distance matrices and an inverse leading-node-finding policy. The method is implemented on a message passing interface (MPI) system. Extensive experiments showed that our method is capable of clustering non-Euclidean data such as in community detection, while outperforming the state-of-the-art counterpart methods in accuracy when clustering large Euclidean data. Our code is publicly available at https://github.com/alanxuji/FaithPDP.
Long-Tailed Classification Based on Coarse-Grained Leading Forest and Multi-Center Loss
Oct 12, 2023Long-tailed(LT) classification is an unavoidable and challenging problem in the real world. Most of the existing long-tailed classification methods focus only on solving the inter-class imbalance in which there are more samples in the head class than in the tail class, while ignoring the intra-lass imbalance in which the number of samples of the head attribute within the same class is much larger than the number of samples of the tail attribute. The deviation in the model is caused by both of these factors, and due to the fact that attributes are implicit in most datasets and the combination of attributes is very complex, the intra-class imbalance is more difficult to handle. For this purpose, we proposed a long-tailed classification framework, known as \textbf{\textsc{Cognisance}}, which is founded on Coarse-Grained Leading Forest (CLF) and Multi-Center Loss (MCL), aiming to build a multi-granularity joint solution model by means of invariant feature learning. In this method, we designed an unsupervised learning method, i.e., CLF, to better characterize the distribution of attributes within a class. Depending on the distribution of attributes, we can flexibly construct sampling strategies suitable for different environments. In addition, we introduce a new metric learning loss (MCL), which aims to gradually eliminate confusing attributes during the feature learning process. More importantly, this approach does not depend on a specific model structure and can be integrated with existing LT methods as an independent component. We have conducted extensive experiments and our approach has state-of-the-art performance in both existing benchmarks ImageNet-GLT and MSCOCO-GLT, and can improve the performance of existing LT methods. Our codes are available on GitHub: \url{https://github.com/jinyery/cognisance}