 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
LLM-Centric RAG with Multi-Granular Indexing and Confidence Constraints
Oct 30, 2025This paper addresses the issues of insufficient coverage, unstable results, and limited reliability in retrieval-augmented generation under complex knowledge environments, and proposes a confidence control method that integrates multi-granularity memory indexing with uncertainty estimation. The method builds a hierarchical memory structure that divides knowledge representations into different levels of granularity, enabling dynamic indexing and retrieval from local details to global context, and thus establishing closer semantic connections between retrieval and generation. On this basis, an uncertainty estimation mechanism is introduced to explicitly constrain and filter low-confidence paths during the generation process, allowing the model to maintain information coverage while effectively suppressing noise and false content. The overall optimization objective consists of generation loss, entropy constraints, and variance regularization, forming a unified confidence control framework. In the experiments, comprehensive sensitivity tests and comparative analyses were designed, covering hyperparameters, environmental conditions, and data structures, to verify the stability and robustness of the proposed method across different scenarios. The results show that the method achieves superior performance over existing models in QA accuracy, retrieval recall, ranking quality, and factual consistency, demonstrating the effectiveness of combining multi-granularity indexing with confidence control. This study not only provides a new technical pathway for retrieval-augmented generation but also offers practical evidence for improving the reliability and controllability of large models in complex contexts.
Topology-Aware Graph Reinforcement Learning for Dynamic Routing in Cloud Networks
Sep 05, 2025This paper proposes a topology-aware graph reinforcement learning approach to address the routing policy optimization problem in cloud server environments. The method builds a unified framework for state representation and structural evolution by integrating a Structure-Aware State Encoding (SASE) module and a Policy-Adaptive Graph Update (PAGU) mechanism. It aims to tackle the challenges of decision instability and insufficient structural awareness under dynamic topologies. The SASE module models node states through multi-layer graph convolution and structural positional embeddings, capturing high-order dependencies in the communication topology and enhancing the expressiveness of state representations. The PAGU module adjusts the graph structure based on policy behavior shifts and reward feedback, enabling adaptive structural updates in dynamic environments. Experiments are conducted on the real-world GEANT topology dataset, where the model is systematically evaluated against several representative baselines in terms of throughput, latency control, and link balance. Additional experiments, including hyperparameter sensitivity, graph sparsity perturbation, and node feature dimensionality variation, further explore the impact of structure modeling and graph updates on model stability and decision quality. Results show that the proposed method outperforms existing graph reinforcement learning models across multiple performance metrics, achieving efficient and robust routing in dynamic and complex cloud networks.
Generalized Low-Rank Matrix Contextual Bandits with Graph Information
Jul 23, 2025The matrix contextual bandit (CB), as an extension of the well-known multi-armed bandit, is a powerful framework that has been widely applied in sequential decision-making scenarios involving low-rank structure. In many real-world scenarios, such as online advertising and recommender systems, additional graph information often exists beyond the low-rank structure, that is, the similar relationships among users/items can be naturally captured through the connectivity among nodes in the corresponding graphs. However, existing matrix CB methods fail to explore such graph information, and thereby making them difficult to generate effective decision-making policies. To fill in this void, we propose in this paper a novel matrix CB algorithmic framework that builds upon the classical upper confidence bound (UCB) framework. This new framework can effectively integrate both the low-rank structure and graph information in a unified manner. Specifically, it involves first solving a joint nuclear norm and matrix Laplacian regularization problem, followed by the implementation of a graph-based generalized linear version of the UCB algorithm. Rigorous theoretical analysis demonstrates that our procedure outperforms several popular alternatives in terms of cumulative regret bound, owing to the effective utilization of graph information. A series of synthetic and real-world data experiments are conducted to further illustrate the merits of our procedure.
Single Index Bandits: Generalized Linear Contextual Bandits with Unknown Reward Functions
Jun 15, 2025Generalized linear bandits have been extensively studied due to their broad applicability in real-world online decision-making problems. However, these methods typically assume that the expected reward function is known to the users, an assumption that is often unrealistic in practice. Misspecification of this link function can lead to the failure of all existing algorithms. In this work, we address this critical limitation by introducing a new problem of generalized linear bandits with unknown reward functions, also known as single index bandits. We first consider the case where the unknown reward function is monotonically increasing, and propose two novel and efficient algorithms, STOR and ESTOR, that achieve decent regrets under standard assumptions. Notably, our ESTOR can obtain the nearly optimal regret bound $\tilde{O}_T(\sqrt{T})$ in terms of the time horizon $T$. We then extend our methods to the high-dimensional sparse setting and show that the same regret rate can be attained with the sparsity index. Next, we introduce GSTOR, an algorithm that is agnostic to general reward functions, and establish regret bounds under a Gaussian design assumption. Finally, we validate the efficiency and effectiveness of our algorithms through experiments on both synthetic and real-world datasets.
Quantum Lipschitz Bandits
Apr 03, 2025The Lipschitz bandit is a key variant of stochastic bandit problems where the expected reward function satisfies a Lipschitz condition with respect to an arm metric space. With its wide-ranging practical applications, various Lipschitz bandit algorithms have been developed, achieving the cumulative regret lower bound of order $\tilde O(T^{(d_z+1)/(d_z+2)})$ over time horizon $T$. Motivated by recent advancements in quantum computing and the demonstrated success of quantum Monte Carlo in simpler bandit settings, we introduce the first quantum Lipschitz bandit algorithms to address the challenges of continuous action spaces and non-linear reward functions. Specifically, we first leverage the elimination-based framework to propose an efficient quantum Lipschitz bandit algorithm named Q-LAE. Next, we present novel modifications to the classical Zooming algorithm, which results in a simple quantum Lipschitz bandit method, Q-Zooming. Both algorithms exploit the computational power of quantum methods to achieve an improved regret bound of $\tilde O(T^{d_z/(d_z+1)})$. Comprehensive experiments further validate our improved theoretical findings, demonstrating superior empirical performance compared to existing Lipschitz bandit methods.
Biased Dueling Bandits with Stochastic Delayed Feedback
Aug 26, 2024
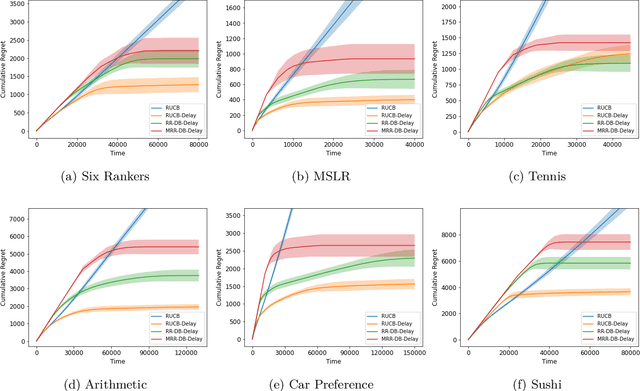
The dueling bandit problem, an essential variation of the traditional multi-armed bandit problem, has become significantly prominent recently due to its broad applications in online advertising, recommendation systems, information retrieval, and more. However, in many real-world applications, the feedback for actions is often subject to unavoidable delays and is not immediately available to the agent. This partially observable issue poses a significant challenge to existing dueling bandit literature, as it significantly affects how quickly and accurately the agent can update their policy on the fly. In this paper, we introduce and examine the biased dueling bandit problem with stochastic delayed feedback, revealing that this new practical problem will delve into a more realistic and intriguing scenario involving a preference bias between the selections. We present two algorithms designed to handle situations involving delay. Our first algorithm, requiring complete delay distribution information, achieves the optimal regret bound for the dueling bandit problem when there is no delay. The second algorithm is tailored for situations where the distribution is unknown, but only the expected value of delay is available. We provide a comprehensive regret analysis for the two proposed algorithms and then evaluate their empirical performance on both synthetic and real datasets.
Low-rank Matrix Bandits with Heavy-tailed Rewards
Apr 26, 2024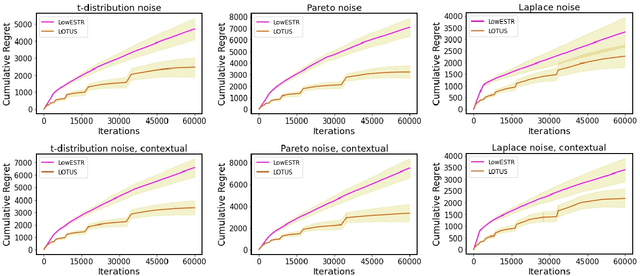
In stochastic low-rank matrix bandit, the expected reward of an arm is equal to the inner product between its feature matrix and some unknown $d_1$ by $d_2$ low-rank parameter matrix $\Theta^*$ with rank $r \ll d_1\wedge d_2$. While all prior studies assume the payoffs are mixed with sub-Gaussian noises, in this work we loosen this strict assumption and consider the new problem of \underline{low}-rank matrix bandit with \underline{h}eavy-\underline{t}ailed \underline{r}ewards (LowHTR), where the rewards only have finite $(1+\delta)$ moment for some $\delta \in (0,1]$. By utilizing the truncation on observed payoffs and the dynamic exploration, we propose a novel algorithm called LOTUS attaining the regret bound of order $\tilde O(d^\frac{3}{2}r^\frac{1}{2}T^\frac{1}{1+\delta}/\tilde{D}_{rr})$ without knowing $T$, which matches the state-of-the-art regret bound under sub-Gaussian noises~\citep{lu2021low,kang2022efficient} with $\delta = 1$. Moreover, we establish a lower bound of the order $\Omega(d^\frac{\delta}{1+\delta} r^\frac{\delta}{1+\delta} T^\frac{1}{1+\delta}) = \Omega(T^\frac{1}{1+\delta})$ for LowHTR, which indicates our LOTUS is nearly optimal in the order of $T$. In addition, we improve LOTUS so that it does not require knowledge of the rank $r$ with $\tilde O(dr^\frac{3}{2}T^\frac{1+\delta}{1+2\delta})$ regret bound, and it is efficient under the high-dimensional scenario. We also conduct simulations to demonstrate the practical superiority of our algorithm.
Efficient Frameworks for Generalized Low-Rank Matrix Bandit Problems
Jan 14, 2024


In the stochastic contextual low-rank matrix bandit problem, the expected reward of an action is given by the inner product between the action's feature matrix and some fixed, but initially unknown $d_1$ by $d_2$ matrix $\Theta^*$ with rank $r \ll \{d_1, d_2\}$, and an agent sequentially takes actions based on past experience to maximize the cumulative reward. In this paper, we study the generalized low-rank matrix bandit problem, which has been recently proposed in \cite{lu2021low} under the Generalized Linear Model (GLM) framework. To overcome the computational infeasibility and theoretical restrain of existing algorithms on this problem, we first propose the G-ESTT framework that modifies the idea from \cite{jun2019bilinear} by using Stein's method on the subspace estimation and then leverage the estimated subspaces via a regularization idea. Furthermore, we remarkably improve the efficiency of G-ESTT by using a novel exclusion idea on the estimated subspace instead, and propose the G-ESTS framework. We also show that G-ESTT can achieve the $\tilde{O}(\sqrt{(d_1+d_2)MrT})$ bound of regret while G-ESTS can achineve the $\tilde{O}(\sqrt{(d_1+d_2)^{3/2}Mr^{3/2}T})$ bound of regret under mild assumption up to logarithm terms, where $M$ is some problem dependent value. Under a reasonable assumption that $M = O((d_1+d_2)^2)$ in our problem setting, the regret of G-ESTT is consistent with the current best regret of $\tilde{O}((d_1+d_2)^{3/2} \sqrt{rT}/D_{rr})$~\citep{lu2021low} ($D_{rr}$ will be defined later). For completeness, we conduct experiments to illustrate that our proposed algorithms, especially G-ESTS, are also computationally tractable and consistently outperform other state-of-the-art (generalized) linear matrix bandit methods based on a suite of simulations.
Try with Simpler -- An Evaluation of Improved Principal Component Analysis in Log-based Anomaly Detection
Aug 24, 2023



The rapid growth of deep learning (DL) has spurred interest in enhancing log-based anomaly detection. This approach aims to extract meaning from log events (log message templates) and develop advanced DL models for anomaly detection. However, these DL methods face challenges like heavy reliance on training data, labels, and computational resources due to model complexity. In contrast, traditional machine learning and data mining techniques are less data-dependent and more efficient but less effective than DL. To make log-based anomaly detection more practical, the goal is to enhance traditional techniques to match DL's effectiveness. Previous research in a different domain (linking questions on Stack Overflow) suggests that optimized traditional techniques can rival state-of-the-art DL methods. Drawing inspiration from this concept, we conducted an empirical study. We optimized the unsupervised PCA (Principal Component Analysis), a traditional technique, by incorporating lightweight semantic-based log representation. This addresses the issue of unseen log events in training data, enhancing log representation. Our study compared seven log-based anomaly detection methods, including four DL-based, two traditional, and the optimized PCA technique, using public and industrial datasets. Results indicate that the optimized unsupervised PCA technique achieves similar effectiveness to advanced supervised/semi-supervised DL methods while being more stable with limited training data and resource-efficient. This demonstrates the adaptability and strength of traditional techniques through small yet impactful adaptations.