 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Matrix Bandits with Heavy-tailed Rewards
Paper and Code
Apr 26, 2024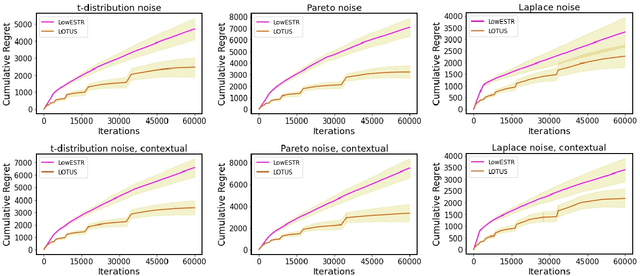
In stochastic low-rank matrix bandit, the expected reward of an arm is equal to the inner product between its feature matrix and some unknown $d_1$ by $d_2$ low-rank parameter matrix $\Theta^*$ with rank $r \ll d_1\wedge d_2$. While all prior studies assume the payoffs are mixed with sub-Gaussian noises, in this work we loosen this strict assumption and consider the new problem of \underline{low}-rank matrix bandit with \underline{h}eavy-\underline{t}ailed \underline{r}ewards (LowHTR), where the rewards only have finite $(1+\delta)$ moment for some $\delta \in (0,1]$. By utilizing the truncation on observed payoffs and the dynamic exploration, we propose a novel algorithm called LOTUS attaining the regret bound of order $\tilde O(d^\frac{3}{2}r^\frac{1}{2}T^\frac{1}{1+\delta}/\tilde{D}_{rr})$ without knowing $T$, which matches the state-of-the-art regret bound under sub-Gaussian noises~\citep{lu2021low,kang2022efficient} with $\delta = 1$. Moreover, we establish a lower bound of the order $\Omega(d^\frac{\delta}{1+\delta} r^\frac{\delta}{1+\delta} T^\frac{1}{1+\delta}) = \Omega(T^\frac{1}{1+\delta})$ for LowHTR, which indicates our LOTUS is nearly optimal in the order of $T$. In addition, we improve LOTUS so that it does not require knowledge of the rank $r$ with $\tilde O(dr^\frac{3}{2}T^\frac{1+\delta}{1+2\delta})$ regret bound, and it is efficient under the high-dimensional scenario. We also conduct simulations to demonstrate the practical superiority of our algorithm.