 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Offline Reinforcement Learning
Paper and Code
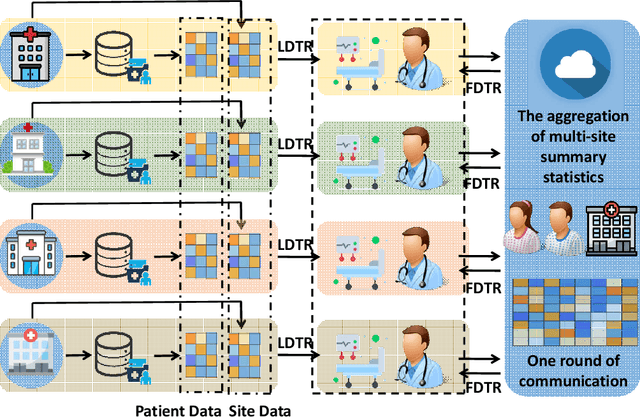
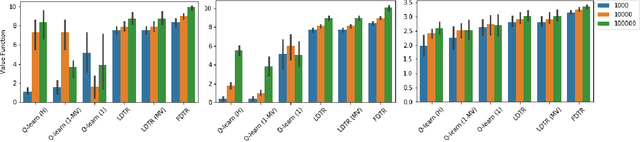
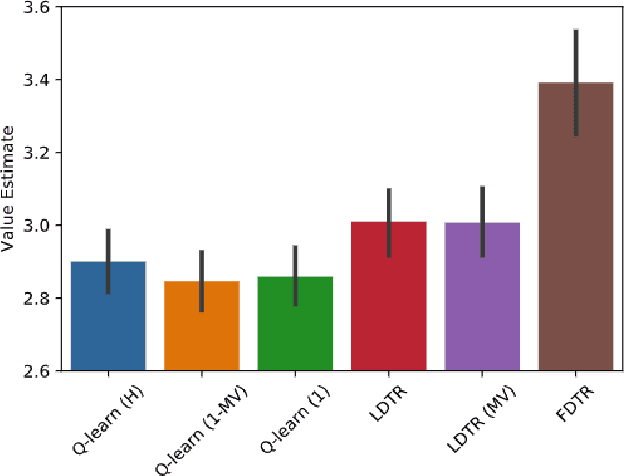
Evidence-based or data-driven dynamic treatment regimes are essential for personalized medicine, which can benefit from offline reinforcement learning (RL). Although massive healthcare data are available across medical institutions, they are prohibited from sharing due to privacy constraints. Besides, heterogeneity exists in different sites. As a result, federated offline RL algorithms are necessary and promising to deal with the problems. In this paper, we propose a multi-site Markov decision process model which allows both homogeneous and heterogeneous effects across sites. The proposed model makes the analysis of the site-level features possible. We design the first federated policy optimization algorithm for offline RL with sample complexity. The proposed algorithm is communication-efficient and privacy-preserving, which requires only a single round of communication interaction by exchanging summary statistics. We give a theoretical guarantee for the proposed algorithm without the assumption of sufficient action coverage, where the suboptimality for the learned policies is comparable to the rate as if data is not distributed. Extensive simulations demonstrate the effectiveness of the proposed algorithm. The method is applied to a sepsis data set in multiple sites to illustrate its use in clinical settings.