 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Interpretability of Recurrent Neural Networks Using Hidden Markov Models
Nov 18, 2016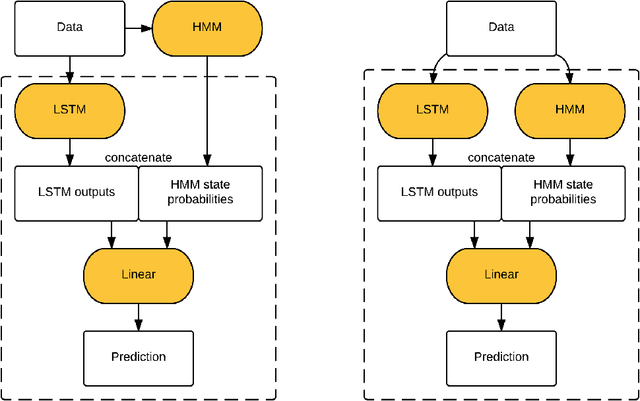
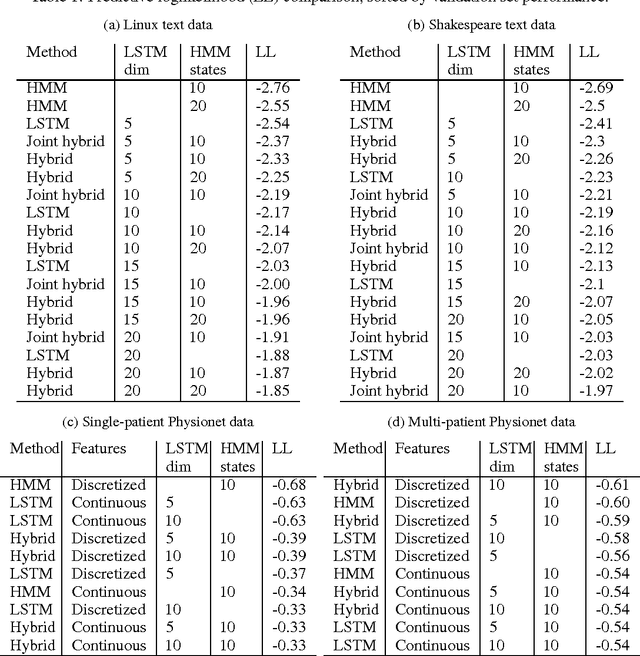
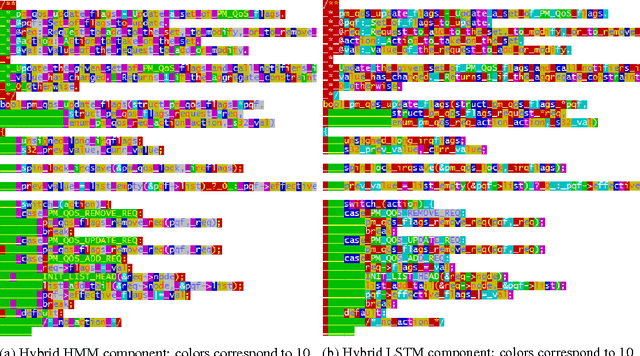
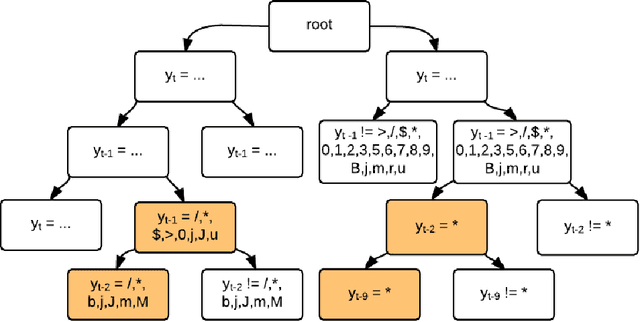
As deep neural networks continue to revolutionize various application domains, there is increasing interest in making these powerful models more understandable and interpretable, and narrowing down the causes of good and bad predictions. We focus on recurrent neural networks, state of the art models in speech recognition and translation. Our approach to increasing interpretability is by combining a long short-term memory (LSTM) model with a hidden Markov model (HMM), a simpler and more transparent model. We add the HMM state probabilities to the output layer of the LSTM, and then train the HMM and LSTM either sequentially or jointly. The LSTM can make use of the information from the HMM, and fill in the gaps when the HMM is not performing well. A small hybrid model usually performs better than a standalone LSTM of the same size, especially on smaller data sets. We test the algorithms on text data and medical time series data, and find that the LSTM and HMM learn complementary information about the features in the text.
A Minimalistic Approach to Sum-Product Network Learning for Real Applications
Apr 24, 2016
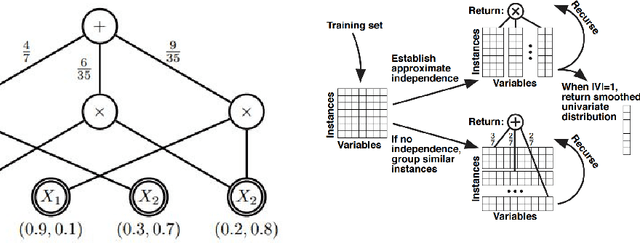
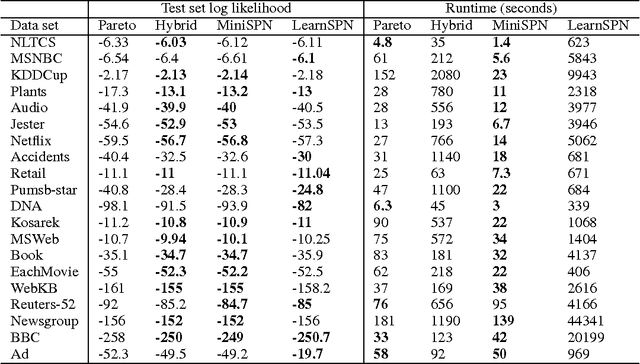
Sum-Product Networks (SPNs) are a class of expressive yet tractable hierarchical graphical models. LearnSPN is a structure learning algorithm for SPNs that uses hierarchical co-clustering to simultaneously identifying similar entities and similar features. The original LearnSPN algorithm assumes that all the variables are discrete and there is no missing data. We introduce a practical, simplified version of LearnSPN, MiniSPN, that runs faster and can handle missing data and heterogeneous features common in real applications. We demonstrate the performance of MiniSPN on standard benchmark datasets and on two datasets from Google's Knowledge Graph exhibiting high missingness rates and a mix of discrete and continuous features.
Interpretable Selection and Visualization of Features and Interactions Using Bayesian Forests
Feb 07, 2016



It is becoming increasingly important for machine learning methods to make predictions that are interpretable as well as accurate. In many practical applications, it is of interest which features and feature interactions are relevant to the prediction task. We present a novel method, Selective Bayesian Forest Classifier, that strikes a balance between predictive power and interpretability by simultaneously performing classification, feature selection, feature interaction detection and visualization. It builds parsimonious yet flexible models using tree-structured Bayesian networks, and samples an ensemble of such models using Markov chain Monte Carlo. We build in feature selection by dividing the trees into two groups according to their relevance to the outcome of interest. Our method performs competitively on classification and feature selection benchmarks in low and high dimensions, and includes a visualization tool that provides insight into relevant features and interactions.