 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Interpretability of Recurrent Neural Networks Using Hidden Markov Models
Paper and Code
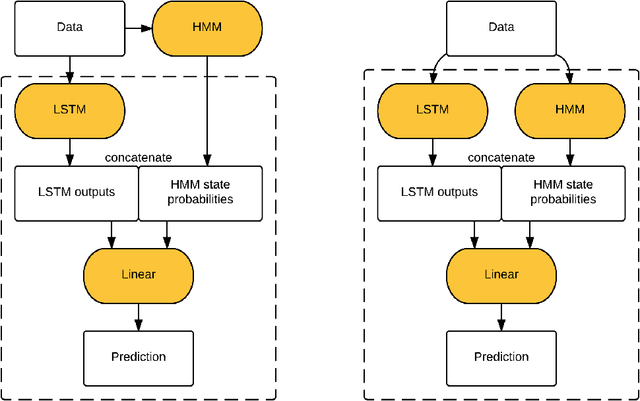
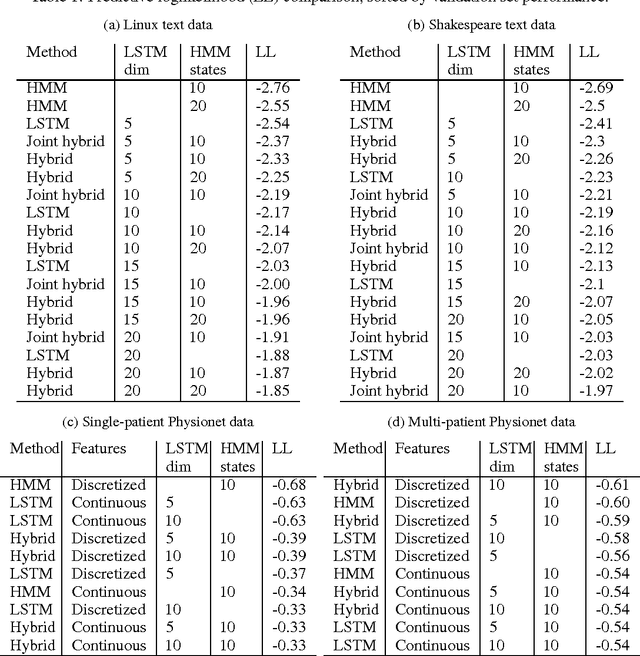
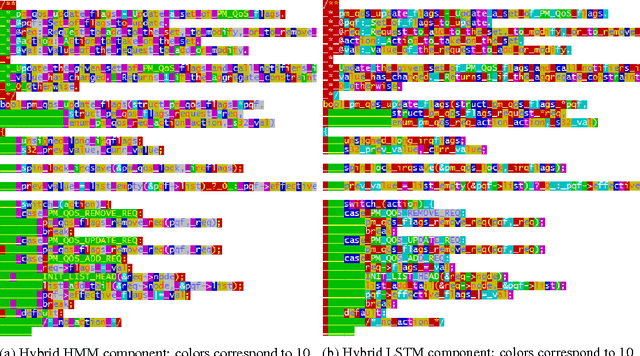
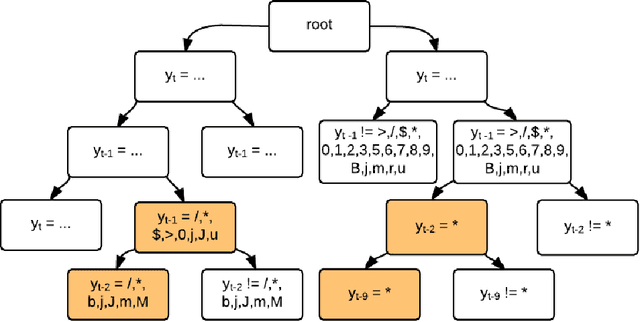
As deep neural networks continue to revolutionize various application domains, there is increasing interest in making these powerful models more understandable and interpretable, and narrowing down the causes of good and bad predictions. We focus on recurrent neural networks, state of the art models in speech recognition and translation. Our approach to increasing interpretability is by combining a long short-term memory (LSTM) model with a hidden Markov model (HMM), a simpler and more transparent model. We add the HMM state probabilities to the output layer of the LSTM, and then train the HMM and LSTM either sequentially or jointly. The LSTM can make use of the information from the HMM, and fill in the gaps when the HMM is not performing well. A small hybrid model usually performs better than a standalone LSTM of the same size, especially on smaller data sets. We test the algorithms on text data and medical time series data, and find that the LSTM and HMM learn complementary information about the features in the text.