 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality for Inherently Explainable Transformers: CAT-XPLAIN
Paper and Code
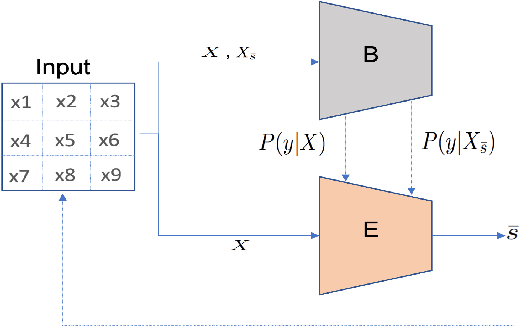
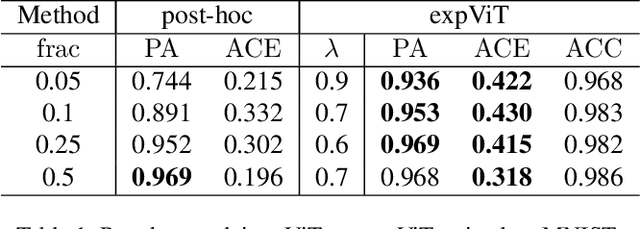
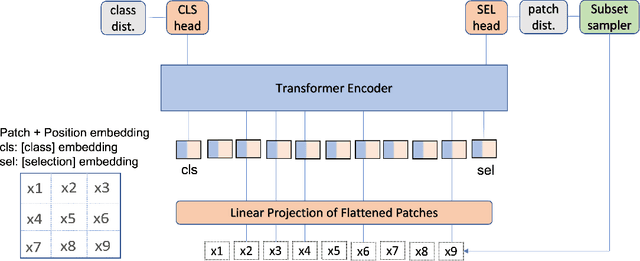
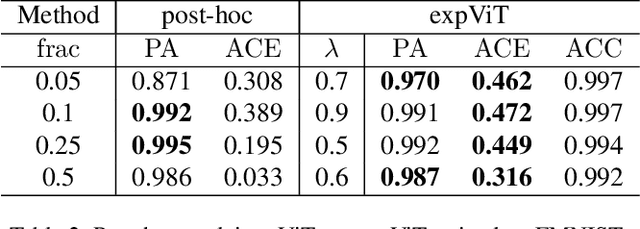
There have been several post-hoc explanation approaches developed to explain pre-trained black-box neural networks. However, there is still a gap in research efforts toward designing neural networks that are inherently explainable. In this paper, we utilize a recently proposed instance-wise post-hoc causal explanation method to make an existing transformer architecture inherently explainable. Once trained, our model provides an explanation in the form of top-$k$ regions in the input space of the given instance contributing to its decision. We evaluate our method on binary classification tasks using three image datasets: MNIST, FMNIST, and CIFAR. Our results demonstrate that compared to the causality-based post-hoc explainer model, our inherently explainable model achieves better explainability results while eliminating the need of training a separate explainer model. Our code is available at https://github.com/mvrl/CAT-XPLAIN.