 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Steffensen method
Paper and Code
Nov 28, 2022
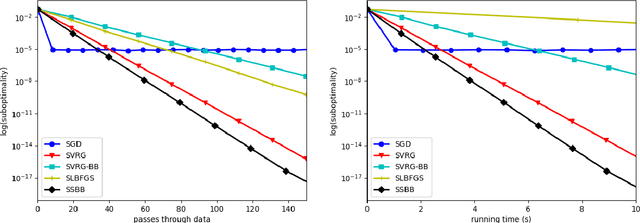
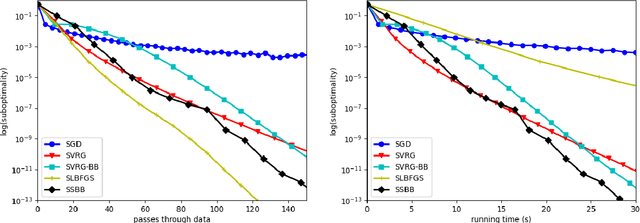
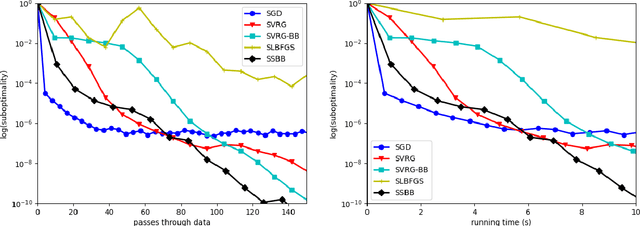
Is it possible for a first-order method, i.e., only first derivatives allowed, to be quadratically convergent? For univariate loss functions, the answer is yes -- the Steffensen method avoids second derivatives and is still quadratically convergent like Newton method. By incorporating an optimal step size we can even push its convergence order beyond quadratic to $1+\sqrt{2} \approx 2.414$. While such high convergence orders are a pointless overkill for a deterministic algorithm, they become rewarding when the algorithm is randomized for problems of massive sizes, as randomization invariably compromises convergence speed. We will introduce two adaptive learning rates inspired by the Steffensen method, intended for use in a stochastic optimization setting and requires no hyperparameter tuning aside from batch size. Extensive experiments show that they compare favorably with several existing first-order methods. When restricted to a quadratic objective, our stochastic Steffensen methods reduce to randomized Kaczmarz method -- note that this is not true for SGD or SLBFGS -- and thus we may also view our methods as a generalization of randomized Kaczmarz to arbitrary objectives.