 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlivenko-Cantelli for $f$-divergence
Mar 21, 2025
We extend the celebrated Glivenko-Cantelli theorem, sometimes called the fundamental theorem of statistics, from its standard setting of total variation distance to all $f$-divergences. A key obstacle in this endeavor is to define $f$-divergence on a subcollection of a $\sigma$-algebra that forms a $\pi$-system but not a $\sigma$-subalgebra. This is a side contribution of our work. We will show that this notion of $f$-divergence on the $\pi$-system of rays preserves nearly all known properties of standard $f$-divergence, yields a novel integral representation of the Kolmogorov-Smirnov distance, and has a Glivenko-Cantelli theorem.
Attention is a smoothed cubic spline
Aug 19, 2024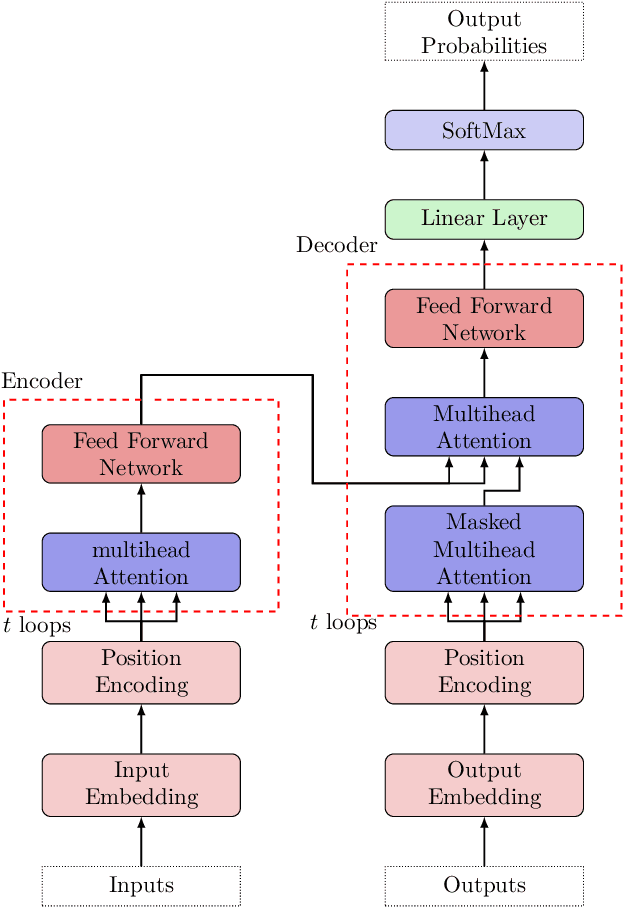
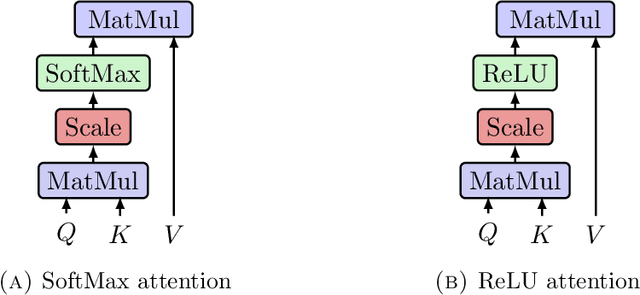
We highlight a perhaps important but hitherto unobserved insight: The attention module in a transformer is a smoothed cubic spline. Viewed in this manner, this mysterious but critical component of a transformer becomes a natural development of an old notion deeply entrenched in classical approximation theory. More precisely, we show that with ReLU-activation, attention, masked attention, encoder-decoder attention are all cubic splines. As every component in a transformer is constructed out of compositions of various attention modules (= cubic splines) and feed forward neural networks (= linear splines), all its components -- encoder, decoder, and encoder-decoder blocks; multilayered encoders and decoders; the transformer itself -- are cubic or higher-order splines. If we assume the Pierce-Birkhoff conjecture, then the converse also holds, i.e., every spline is a ReLU-activated encoder. Since a spline is generally just $C^2$, one way to obtain a smoothed $C^\infty$-version is by replacing ReLU with a smooth activation; and if this activation is chosen to be SoftMax, we recover the original transformer as proposed by Vaswani et al. This insight sheds light on the nature of the transformer by casting it entirely in terms of splines, one of the best known and thoroughly understood objects in applied mathematics.
Stochastic Steffensen method
Nov 28, 2022
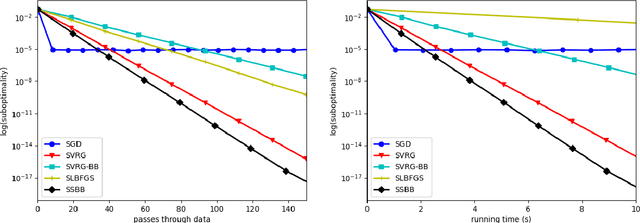
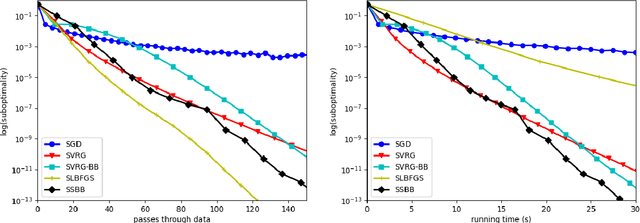
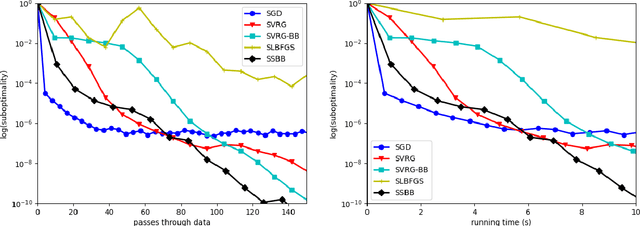
Is it possible for a first-order method, i.e., only first derivatives allowed, to be quadratically convergent? For univariate loss functions, the answer is yes -- the Steffensen method avoids second derivatives and is still quadratically convergent like Newton method. By incorporating an optimal step size we can even push its convergence order beyond quadratic to $1+\sqrt{2} \approx 2.414$. While such high convergence orders are a pointless overkill for a deterministic algorithm, they become rewarding when the algorithm is randomized for problems of massive sizes, as randomization invariably compromises convergence speed. We will introduce two adaptive learning rates inspired by the Steffensen method, intended for use in a stochastic optimization setting and requires no hyperparameter tuning aside from batch size. Extensive experiments show that they compare favorably with several existing first-order methods. When restricted to a quadratic objective, our stochastic Steffensen methods reduce to randomized Kaczmarz method -- note that this is not true for SGD or SLBFGS -- and thus we may also view our methods as a generalization of randomized Kaczmarz to arbitrary objectives.
LU decomposition and Toeplitz decomposition of a neural network
Nov 25, 2022It is well-known that any matrix $A$ has an LU decomposition. Less well-known is the fact that it has a 'Toeplitz decomposition' $A = T_1 T_2 \cdots T_r$ where $T_i$'s are Toeplitz matrices. We will prove that any continuous function $f : \mathbb{R}^n \to \mathbb{R}^m$ has an approximation to arbitrary accuracy by a neural network that takes the form $L_1 \sigma_1 U_1 \sigma_2 L_2 \sigma_3 U_2 \cdots L_r \sigma_{2r-1} U_r$, i.e., where the weight matrices alternate between lower and upper triangular matrices, $\sigma_i(x) := \sigma(x - b_i)$ for some bias vector $b_i$, and the activation $\sigma$ may be chosen to be essentially any uniformly continuous nonpolynomial function. The same result also holds with Toeplitz matrices, i.e., $f \approx T_1 \sigma_1 T_2 \sigma_2 \cdots \sigma_{r-1} T_r$ to arbitrary accuracy, and likewise for Hankel matrices. A consequence of our Toeplitz result is a fixed-width universal approximation theorem for convolutional neural networks, which so far have only arbitrary width versions. Since our results apply in particular to the case when $f$ is a general neural network, we may regard them as LU and Toeplitz decompositions of a neural network. The practical implication of our results is that one may vastly reduce the number of weight parameters in a neural network without sacrificing its power of universal approximation. We will present several experiments on real data sets to show that imposing such structures on the weight matrices sharply reduces the number of training parameters with almost no noticeable effect on test accuracy.
What is an equivariant neural network?
May 15, 2022
We explain equivariant neural networks, a notion underlying breakthroughs in machine learning from deep convolutional neural networks for computer vision to AlphaFold 2 for protein structure prediction, without assuming knowledge of equivariance or neural networks. The basic mathematical ideas are simple but are often obscured by engineering complications that come with practical realizations. We extract and focus on the mathematical aspects, and limit ourselves to a cursory treatment of the engineering issues at the end.
Recht-Ré Noncommutative Arithmetic-Geometric Mean Conjecture is False
Jun 02, 2020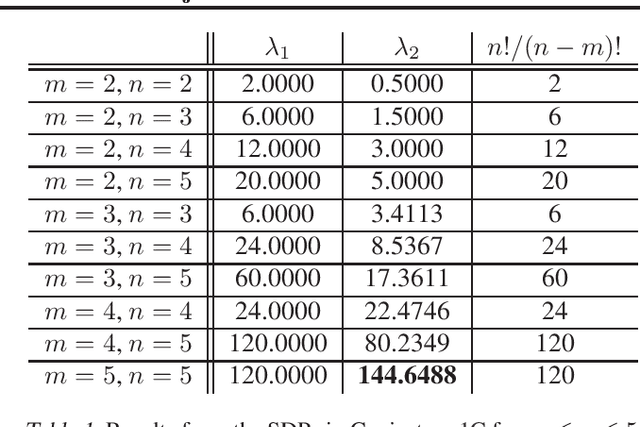
Stochastic optimization algorithms have become indispensable in modern machine learning. An unresolved foundational question in this area is the difference between with-replacement sampling and without-replacement sampling -- does the latter have superior convergence rate compared to the former? A groundbreaking result of Recht and R\'e reduces the problem to a noncommutative analogue of the arithmetic-geometric mean inequality where $n$ positive numbers are replaced by $n$ positive definite matrices. If this inequality holds for all $n$, then without-replacement sampling indeed outperforms with-replacement sampling. The conjectured Recht-R\'e inequality has so far only been established for $n = 2$ and a special case of $n = 3$. We will show that the Recht-R\'e conjecture is false for general $n$. Our approach relies on the noncommutative Positivstellensatz, which allows us to reduce the conjectured inequality to a semidefinite program and the validity of the conjecture to certain bounds for the optimum values, which we show are false as soon as $n = 5$.
* 10 pages
Topology of deep neural networks
Apr 13, 2020


We study how the topology of a data set $M = M_a \cup M_b \subseteq \mathbb{R}^d$, representing two classes $a$ and $b$ in a binary classification problem, changes as it passes through the layers of a well-trained neural network, i.e., with perfect accuracy on training set and near-zero generalization error ($\approx 0.01\%$). The goal is to shed light on two mysteries in deep neural networks: (i) a nonsmooth activation function like ReLU outperforms a smooth one like hyperbolic tangent; (ii) successful neural network architectures rely on having many layers, even though a shallow network can approximate any function arbitrary well. We performed extensive experiments on the persistent homology of a wide range of point cloud data sets, both real and simulated. The results consistently demonstrate the following: (1) Neural networks operate by changing topology, transforming a topologically complicated data set into a topologically simple one as it passes through the layers. No matter how complicated the topology of $M$ we begin with, when passed through a well-trained neural network $f : \mathbb{R}^d \to \mathbb{R}^p$, there is a vast reduction in the Betti numbers of both components $M_a$ and $M_b$; in fact they nearly always reduce to their lowest possible values: $\beta_k\bigl(f(M_i)\bigr) = 0$ for $k \ge 1$ and $\beta_0\bigl(f(M_i)\bigr) = 1$, $i =a, b$. Furthermore, (2) the reduction in Betti numbers is significantly faster for ReLU activation than hyperbolic tangent activation as the former defines nonhomeomorphic maps that change topology, whereas the latter defines homeomorphic maps that preserve topology. Lastly, (3) shallow and deep networks transform data sets differently -- a shallow network operates mainly through changing geometry and changes topology only in its final layers, a deep one spreads topological changes more evenly across all layers.
Best k-layer neural network approximations
Jul 02, 2019We investigate the geometry of the empirical risk minimization problem for $k$-layer neural networks. We will provide examples showing that for the classical activation functions $\sigma(x)= 1/\bigl(1 + \exp(-x)\bigr)$ and $\sigma(x)=\tanh(x)$, there exists a positive-measured subset of target functions that do not have best approximations by a fixed number of layers of neural networks. In addition, we study in detail the properties of shallow networks, classifying cases when a best $k$-layer neural network approximation always exists or does not exist for the ReLU activation $\sigma=\max(0,x)$. We also determine the dimensions of shallow ReLU-activated networks.
Tropical Geometry of Deep Neural Networks
May 18, 2018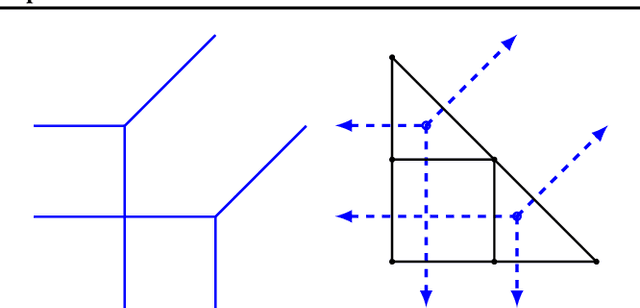

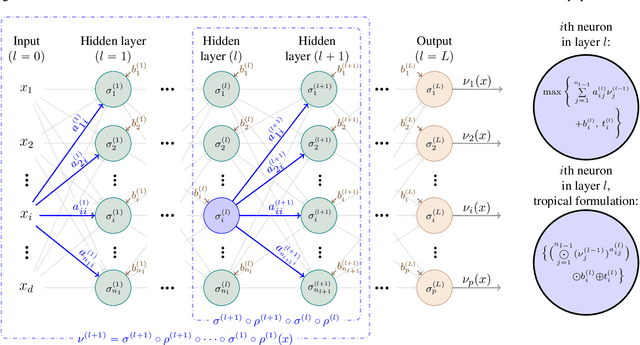
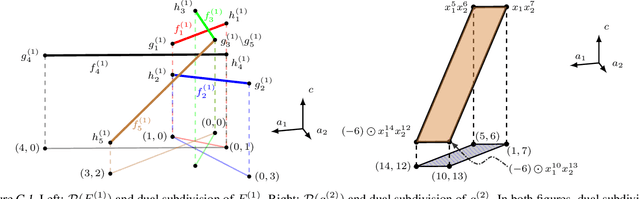
We establish, for the first time, connections between feedforward neural networks with ReLU activation and tropical geometry --- we show that the family of such neural networks is equivalent to the family of tropical rational maps. Among other things, we deduce that feedforward ReLU neural networks with one hidden layer can be characterized by zonotopes, which serve as building blocks for deeper networks; we relate decision boundaries of such neural networks to tropical hypersurfaces, a major object of study in tropical geometry; and we prove that linear regions of such neural networks correspond to vertices of polytopes associated with tropical rational functions. An insight from our tropical formulation is that a deeper network is exponentially more expressive than a shallow network.
* 18 pages, 6 figures
Cohomology of Cryo-Electron Microscopy
Apr 22, 2017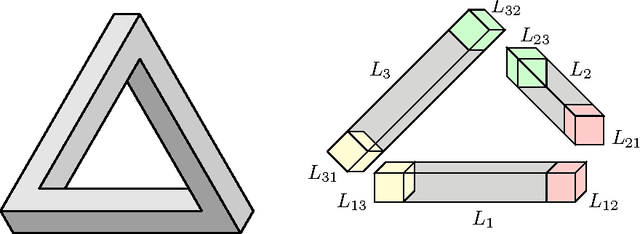
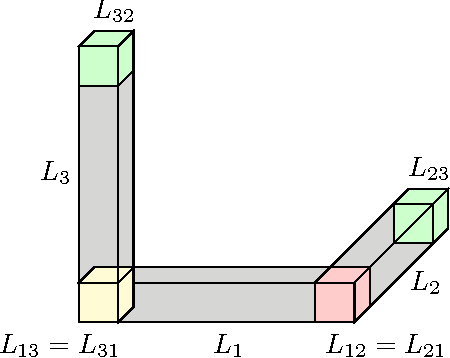

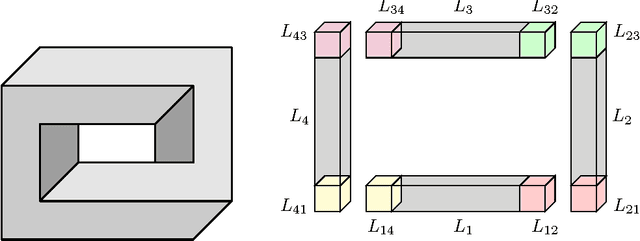
The goal of cryo-electron microscopy (EM) is to reconstruct the 3-dimensional structure of a molecule from a collection of its 2-dimensional projected images. In this article, we show that the basic premise of cryo-EM --- patching together 2-dimensional projections to reconstruct a 3-dimensional object --- is naturally one of Cech cohomology with SO(2)-coefficients. We deduce that every cryo-EM reconstruction problem corresponds to an oriented circle bundle on a simplicial complex, allowing us to classify cryo-EM problems via principal bundles. In practice, the 2-dimensional images are noisy and a main task in cryo-EM is to denoise them. We will see how the aforementioned insights can be used towards this end.