 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology of deep neural networks
Paper and Code

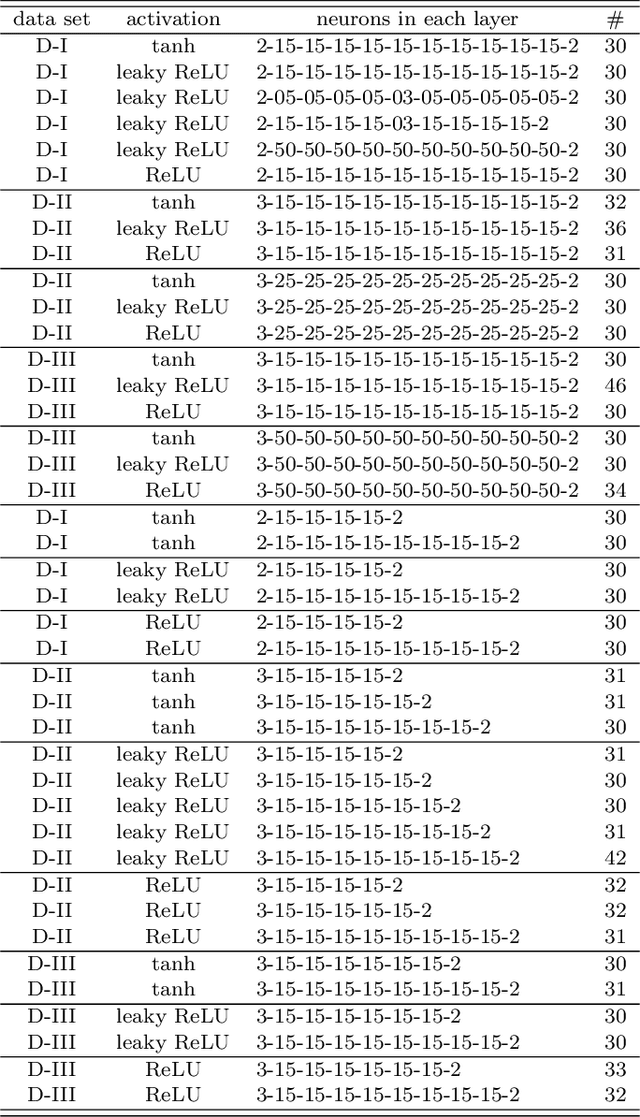


We study how the topology of a data set $M = M_a \cup M_b \subseteq \mathbb{R}^d$, representing two classes $a$ and $b$ in a binary classification problem, changes as it passes through the layers of a well-trained neural network, i.e., with perfect accuracy on training set and near-zero generalization error ($\approx 0.01\%$). The goal is to shed light on two mysteries in deep neural networks: (i) a nonsmooth activation function like ReLU outperforms a smooth one like hyperbolic tangent; (ii) successful neural network architectures rely on having many layers, even though a shallow network can approximate any function arbitrary well. We performed extensive experiments on the persistent homology of a wide range of point cloud data sets, both real and simulated. The results consistently demonstrate the following: (1) Neural networks operate by changing topology, transforming a topologically complicated data set into a topologically simple one as it passes through the layers. No matter how complicated the topology of $M$ we begin with, when passed through a well-trained neural network $f : \mathbb{R}^d \to \mathbb{R}^p$, there is a vast reduction in the Betti numbers of both components $M_a$ and $M_b$; in fact they nearly always reduce to their lowest possible values: $\beta_k\bigl(f(M_i)\bigr) = 0$ for $k \ge 1$ and $\beta_0\bigl(f(M_i)\bigr) = 1$, $i =a, b$. Furthermore, (2) the reduction in Betti numbers is significantly faster for ReLU activation than hyperbolic tangent activation as the former defines nonhomeomorphic maps that change topology, whereas the latter defines homeomorphic maps that preserve topology. Lastly, (3) shallow and deep networks transform data sets differently -- a shallow network operates mainly through changing geometry and changes topology only in its final layers, a deep one spreads topological changes more evenly across all layers.