 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention is a smoothed cubic spline
Paper and Code
Aug 19, 2024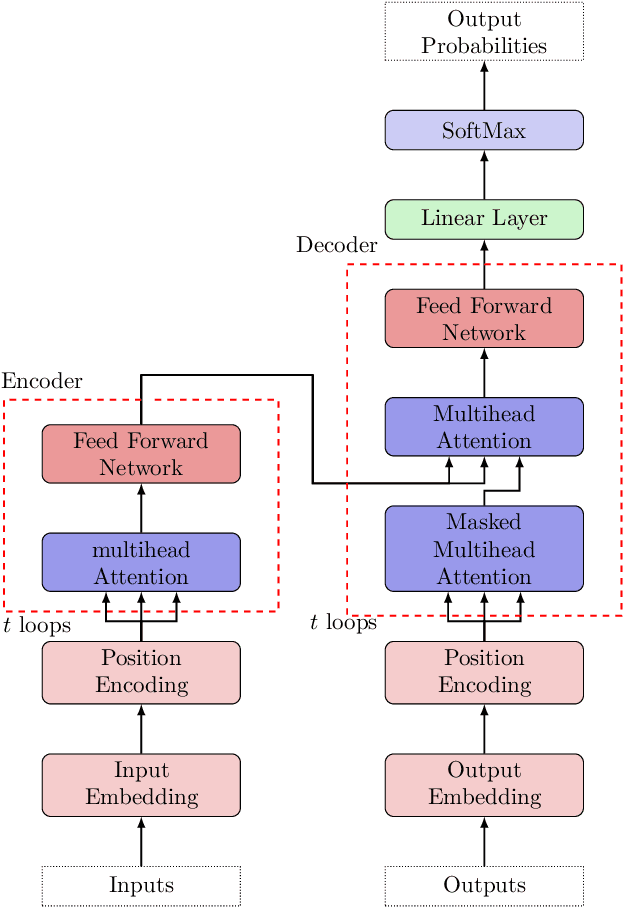
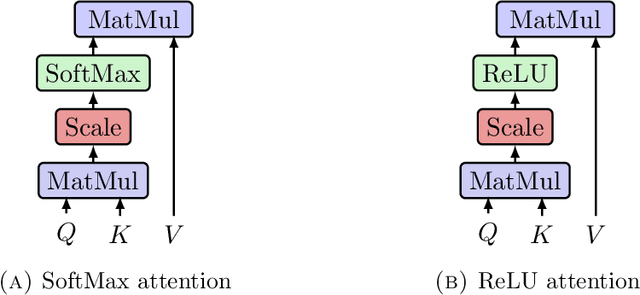
We highlight a perhaps important but hitherto unobserved insight: The attention module in a transformer is a smoothed cubic spline. Viewed in this manner, this mysterious but critical component of a transformer becomes a natural development of an old notion deeply entrenched in classical approximation theory. More precisely, we show that with ReLU-activation, attention, masked attention, encoder-decoder attention are all cubic splines. As every component in a transformer is constructed out of compositions of various attention modules (= cubic splines) and feed forward neural networks (= linear splines), all its components -- encoder, decoder, and encoder-decoder blocks; multilayered encoders and decoders; the transformer itself -- are cubic or higher-order splines. If we assume the Pierce-Birkhoff conjecture, then the converse also holds, i.e., every spline is a ReLU-activated encoder. Since a spline is generally just $C^2$, one way to obtain a smoothed $C^\infty$-version is by replacing ReLU with a smooth activation; and if this activation is chosen to be SoftMax, we recover the original transformer as proposed by Vaswani et al. This insight sheds light on the nature of the transformer by casting it entirely in terms of splines, one of the best known and thoroughly understood objects in applied mathematics.