 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmirati-Accented Speaker Identification in Stressful Talking Conditions
Paper and Code
Oct 29, 2019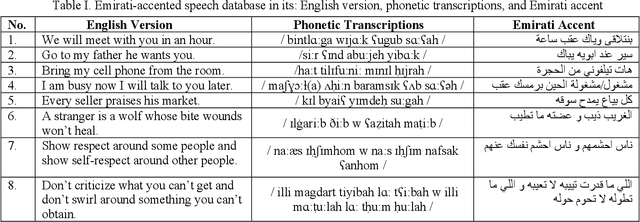
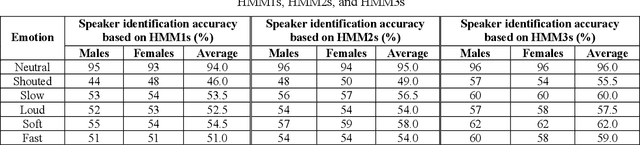
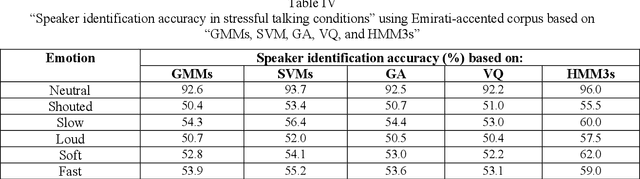
This research is dedicated to improving text-independent Emirati-accented speaker identification performance in stressful talking conditions using three distinct classifiers: First-Order Hidden Markov Models (HMM1s), Second-Order Hidden Markov Models (HMM2s), and Third-Order Hidden Markov Models (HMM3s). The database that has been used in this work was collected from 25 per gender Emirati native speakers uttering eight widespread Emirati sentences in each of neutral, shouted, slow, loud, soft, and fast talking conditions. The extracted features of the captured database are called Mel-Frequency Cepstral Coefficients (MFCCs). Based on HMM1s, HMM2s, and HMM3s, average Emirati-accented speaker identification accuracy in stressful conditions is 58.6%, 61.1%, and 65.0%, respectively. The achieved average speaker identification accuracy in stressful conditions based on HMM3s is so similar to that attained in subjective assessment by human listeners.