 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition Using Speaker Cues
Paper and Code
Feb 04, 2020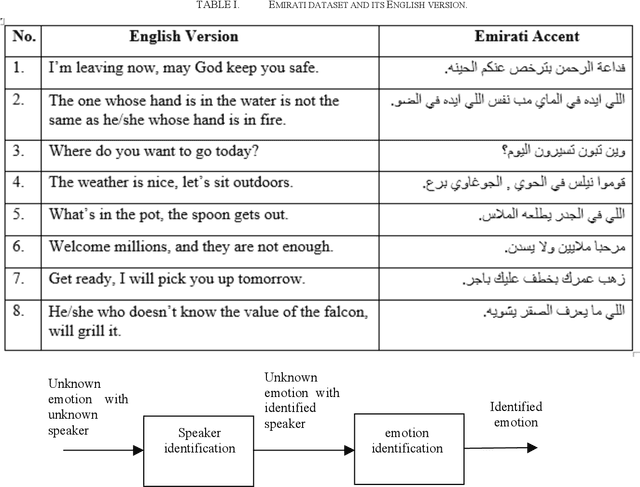
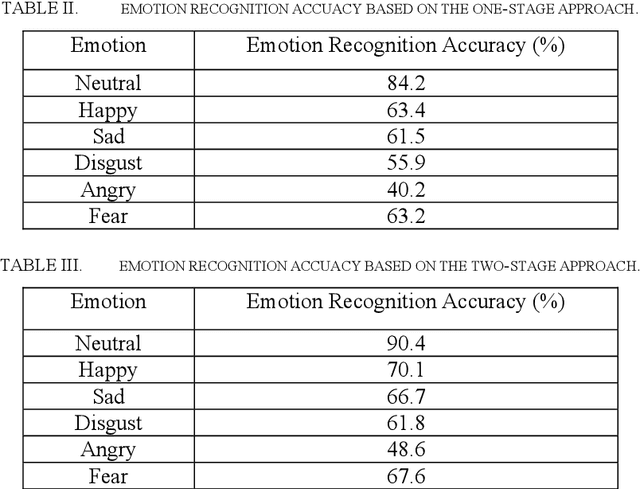
This research aims at identifying the unknown emotion using speaker cues. In this study, we identify the unknown emotion using a two-stage framework. The first stage focuses on identifying the speaker who uttered the unknown emotion, while the next stage focuses on identifying the unknown emotion uttered by the recognized speaker in the prior stage. This proposed framework has been evaluated on an Arabic Emirati-accented speech database uttered by fifteen speakers per gender. Mel-Frequency Cepstral Coefficients (MFCCs) have been used as the extracted features and Hidden Markov Model (HMM) has been utilized as the classifier in this work. Our findings demonstrate that emotion recognition accuracy based on the two-stage framework is greater than that based on the one-stage approach and the state-of-the-art classifiers and models such as Gaussian Mixture Model (GMM), Support Vector Machine (SVM), and Vector Quantization (VQ). The average emotion recognition accuracy based on the two-stage approach is 67.5%, while the accuracy reaches to 61.4%, 63.3%, 64.5%, and 61.5%, based on the one-stage approach, GMM, SVM, and VQ, respectively. The achieved results based on the two-stage framework are very close to those attained in subjective assessment by human listeners.