 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Identification from emotional and noisy speech data using learned voice segregation and Speech VGG
Oct 23, 2022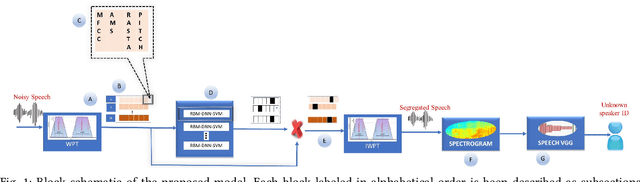
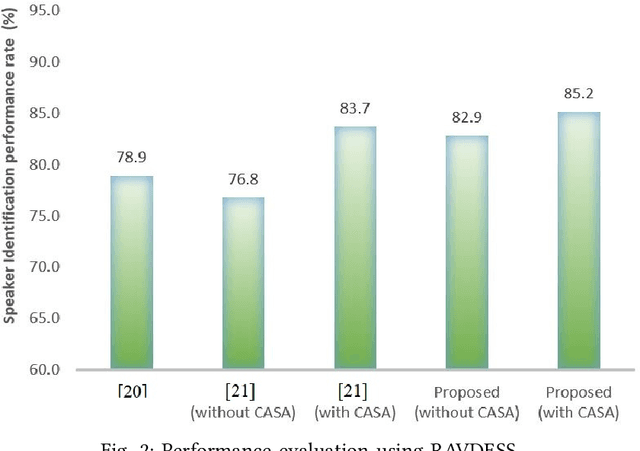
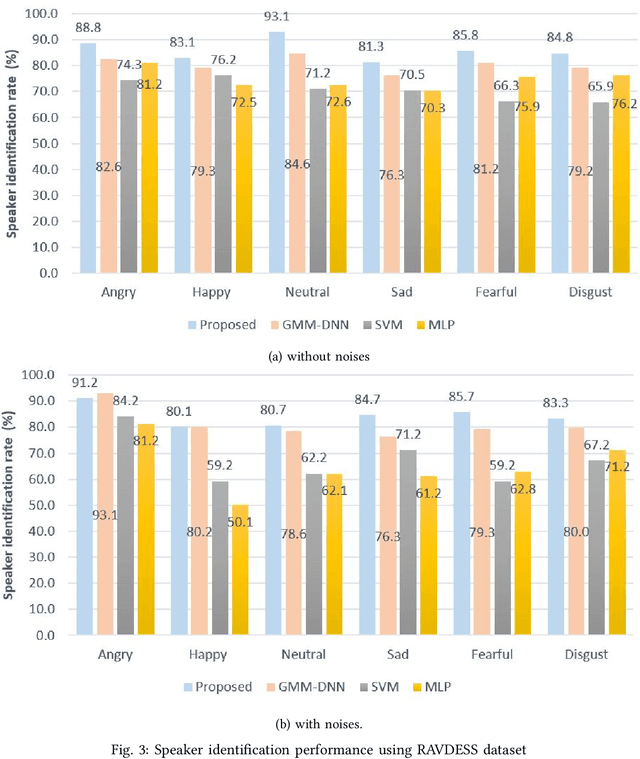
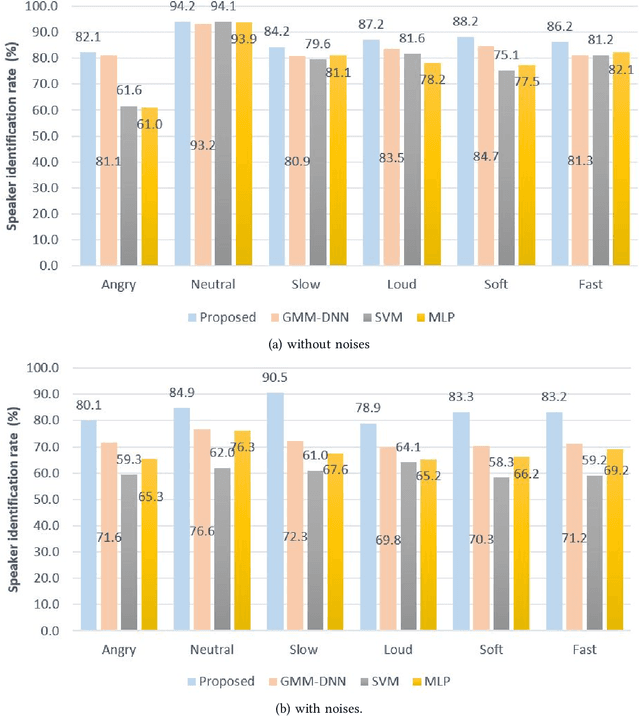
Speech signals are subjected to more acoustic interference and emotional factors than other signals. Noisy emotion-riddled speech data is a challenge for real-time speech processing applications. It is essential to find an effective way to segregate the dominant signal from other external influences. An ideal system should have the capacity to accurately recognize required auditory events from a complex scene taken in an unfavorable situation. This paper proposes a novel approach to speaker identification in unfavorable conditions such as emotion and interference using a pre-trained Deep Neural Network mask and speech VGG. The proposed model obtained superior performance over the recent literature in English and Arabic emotional speech data and reported an average speaker identification rate of 85.2\%, 87.0\%, and 86.6\% using the Ryerson audio-visual dataset (RAVDESS), speech under simulated and actual stress (SUSAS) dataset and Emirati-accented Speech dataset (ESD) respectively.