 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow2Deep: Indoor Scene Modeling by Single Image Understanding
Paper and Code
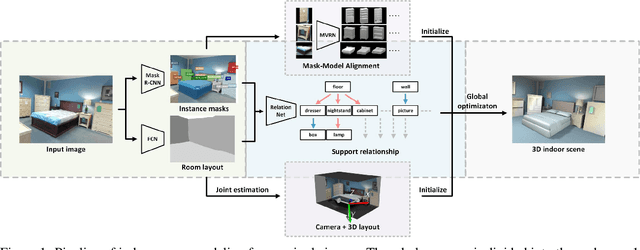



Dense indoor scene modeling from 2D images has been bottlenecked due to the absence of depth information and cluttered occlusions. We present an automatic indoor scene modeling approach using deep features from neural networks. Given a single RGB image, our method simultaneously recovers semantic contents, 3D geometry and object relationship by reasoning indoor environment context. Particularly, we design a shallow-to-deep architecture on the basis of convolutional networks for semantic scene understanding and modeling. It involves multi-level convolutional networks to parse indoor semantics/geometry into non-relational and relational knowledge. Non-relational knowledge extracted from shallow-end networks (e.g. room layout, object geometry) is fed forward into deeper levels to parse relational semantics (e.g. support relationship). A Relation Network is proposed to infer the support relationship between objects. All the structured semantics and geometry above are assembled to guide a global optimization for 3D scene modeling. Qualitative and quantitative analysis demonstrates the feasibility of our method in understanding and modeling semantics-enriched indoor scenes by evaluating the performance of reconstruction accuracy, computation performance and scene complexity.