 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULD@NUIG at SemEval-2020 Task 9: Generative Morphemes with an Attention Model for Sentiment Analysis in Code-Mixed Text
Paper and Code
Jul 27, 2020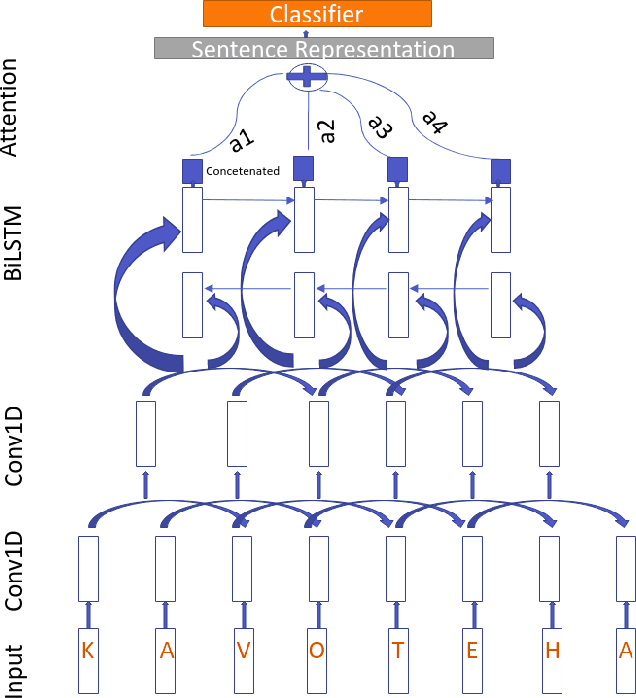
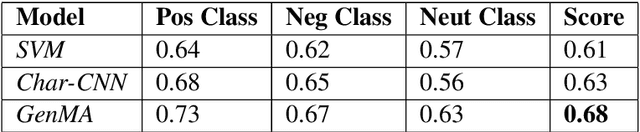
Code mixing is a common phenomena in multilingual societies where people switch from one language to another for various reasons. Recent advances in public communication over different social media sites have led to an increase in the frequency of code-mixed usage in written language. In this paper, we present the Generative Morphemes with Attention (GenMA) Model sentiment analysis system contributed to SemEval 2020 Task 9 SentiMix. The system aims to predict the sentiments of the given English-Hindi code-mixed tweets without using word-level language tags instead inferring this automatically using a morphological model. The system is based on a novel deep neural network (DNN) architecture, which has outperformed the baseline F1-score on the test data-set as well as the validation data-set. Our results can be found under the user name "koustava" on the "Sentimix Hindi English" page