 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview of Indian Language Datasets used for Text Summarization
Apr 01, 2022
In this paper, we survey Text Summarization (TS) datasets in Indian Languages (ILs), which are also low-resource languages (LRLs). We seek to answer one primary question: is the pool of Indian Language Text Summarization (ILTS) dataset growing or is there a resource poverty? To an-swer the primary question, we pose two sub-questions that we seek about ILTS datasets: first, what characteristics: format and domain do ILTS datasets have? Second, how different are those characteristics of ILTS datasets from high-resource languages (HRLs) particularly English. We focus on datasets reported in published ILTS research works during 2012-2022. The survey of ILTS and English datasets reveals two similarities and one contrast. The two similarities are: first, the domain of dataset commonly is news (Hermann et al., 2015). The second similarity is the format of the dataset which is both extractive and abstractive. The contrast is in how the research in dataset development has progressed. ILs face a slow speed of development and public release of datasets as compared with English. We argue that the relatively lower number of ILTS datasets is because of two reasons: first, absence of a dedicated forum for developing TS tools and resources; and second, lack of shareable standard datasets in the public domain.
Prosody Labelled Dataset for Hindi using Semi-Automated Approach
Dec 11, 2021
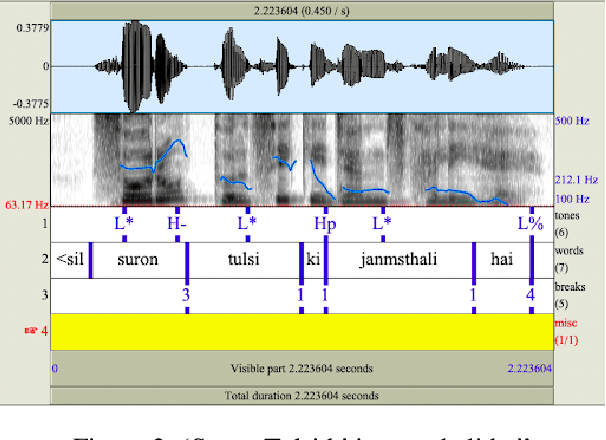
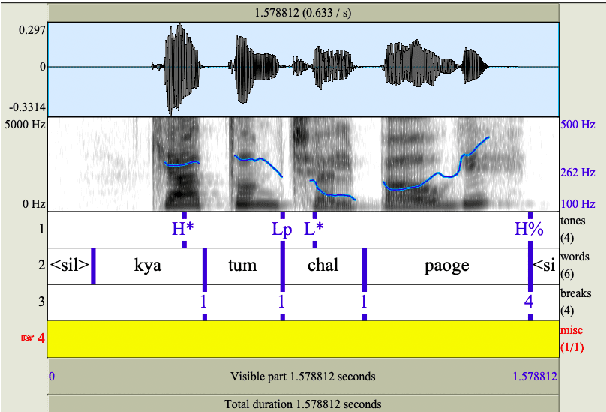
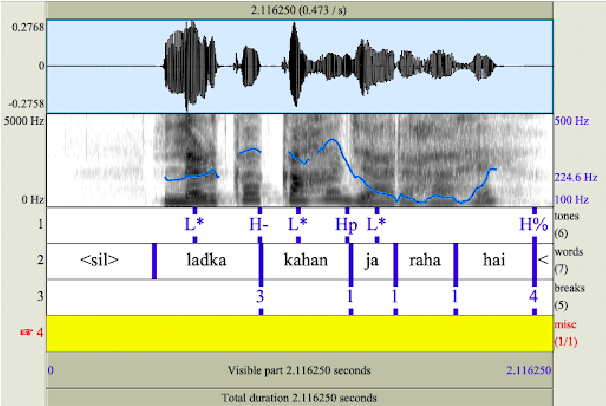
This study aims to develop a semi-automatically labelled prosody database for Hindi, for enhancing the intonation component in ASR and TTS systems, which is also helpful for building Speech to Speech Machine Translation systems. Although no single standard for prosody labelling exists in Hindi, researchers in the past have employed perceptual and statistical methods in literature to draw inferences about the behaviour of prosody patterns in Hindi. Based on such existing research and largely agreed upon theories of intonation in Hindi, this study attempts to first develop a manually annotated prosodic corpus of Hindi speech data, which is then used for training prediction models for generating automatic prosodic labels. A total of 5,000 sentences (23,500 words) for declarative and interrogative types have been labelled. The accuracy of the trained models for pitch accent, intermediate phrase boundaries and accentual phrase boundaries is 73.40%, 93.20%, and 43% respectively.
Translating Politeness Across Cultures: Case of Hindi and English
Dec 03, 2021In this paper, we present a corpus based study of politeness across two languages-English and Hindi. It studies the politeness in a translated parallel corpus of Hindi and English and sees how politeness in a Hindi text is translated into English. We provide a detailed theoretical background in which the comparison is carried out, followed by a brief description of the translated data within this theoretical model. Since politeness may become one of the major reasons of conflict and misunderstanding, it is a very important phenomenon to be studied and understood cross-culturally, particularly for such purposes as machine translation.
Creating and Managing a large annotated parallel corpora of Indian languages
Dec 03, 2021This paper presents the challenges in creating and managing large parallel corpora of 12 major Indian languages (which is soon to be extended to 23 languages) as part of a major consortium project funded by the Department of Information Technology (DIT), Govt. of India, and running parallel in 10 different universities of India. In order to efficiently manage the process of creation and dissemination of these huge corpora, the web-based (with a reduced stand-alone version also) annotation tool ILCIANN (Indian Languages Corpora Initiative Annotation Tool) has been developed. It was primarily developed for the POS annotation as well as the management of the corpus annotation by people with differing amount of competence and at locations physically situated far apart. In order to maintain consistency and standards in the creation of the corpora, it was necessary that everyone works on a common platform which was provided by this tool.
Demo of Sanskrit-Hindi SMT System
Apr 13, 2018

The demo proposal presents a Phrase-based Sanskrit-Hindi (SaHiT) Statistical Machine Translation system. The system has been developed on Moses. 43k sentences of Sanskrit-Hindi parallel corpus and 56k sentences of a monolingual corpus in the target language (Hindi) have been used. This system gives 57 BLEU score.
* Proceedings of the 4th Workshop on Indian Language Data: Resources and Evaluation (under the 11th LREC2018, May 07-12, 2018)
Automatic Language Identification System for Hindi and Magahi
Apr 13, 2018
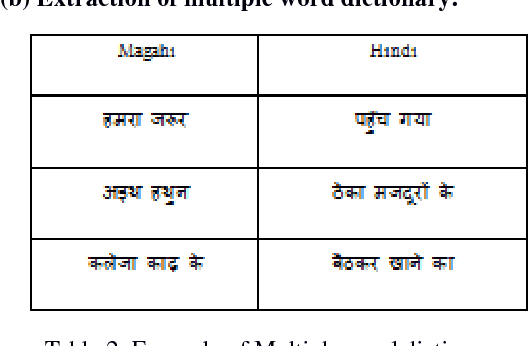
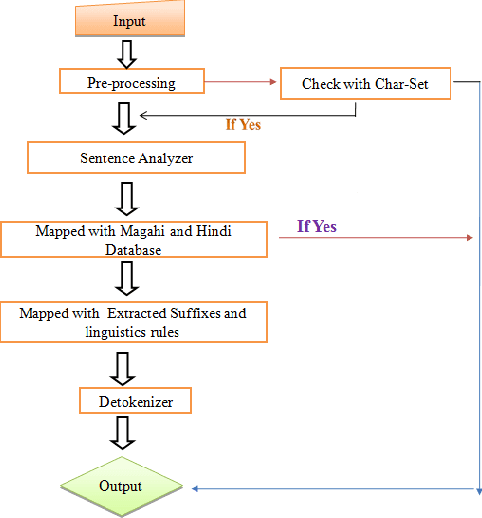
Language identification has become a prerequisite for all kinds of automated text processing systems. In this paper, we present a rule-based language identifier tool for two closely related Indo-Aryan languages: Hindi and Magahi. This system has currently achieved an accuracy of approx 86.34%. We hope to improve this in the future. Automatic identification of languages will be significant in the accuracy of output of Web Crawlers.