 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody Labelled Dataset for Hindi using Semi-Automated Approach
Dec 11, 2021
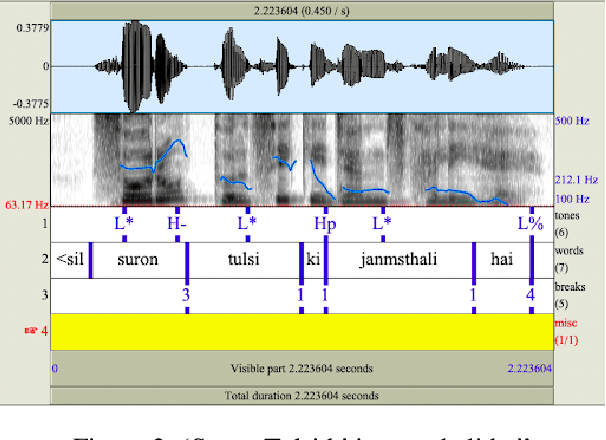
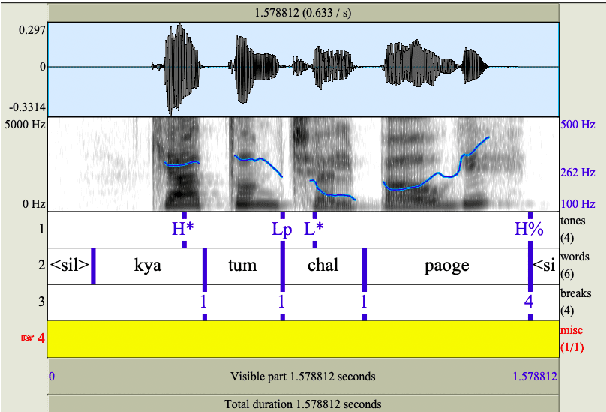
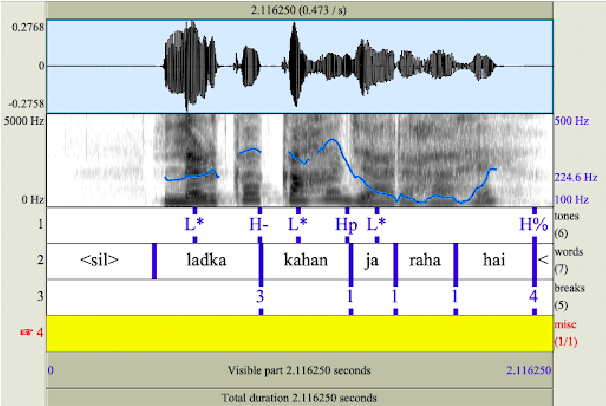
This study aims to develop a semi-automatically labelled prosody database for Hindi, for enhancing the intonation component in ASR and TTS systems, which is also helpful for building Speech to Speech Machine Translation systems. Although no single standard for prosody labelling exists in Hindi, researchers in the past have employed perceptual and statistical methods in literature to draw inferences about the behaviour of prosody patterns in Hindi. Based on such existing research and largely agreed upon theories of intonation in Hindi, this study attempts to first develop a manually annotated prosodic corpus of Hindi speech data, which is then used for training prediction models for generating automatic prosodic labels. A total of 5,000 sentences (23,500 words) for declarative and interrogative types have been labelled. The accuracy of the trained models for pitch accent, intermediate phrase boundaries and accentual phrase boundaries is 73.40%, 93.20%, and 43% respectively.