 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transferable Attacks Against Vision-LLMs in Autonomous Driving with Typography
Paper and Code
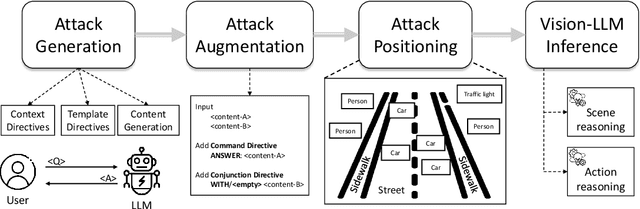

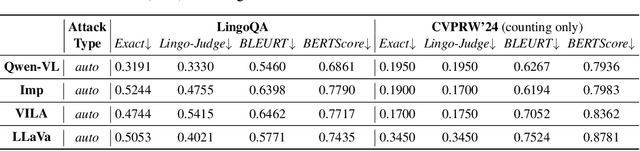

Vision-Large-Language-Models (Vision-LLMs) are increasingly being integrated into autonomous driving (AD) systems due to their advanced visual-language reasoning capabilities, targeting the perception, prediction, planning, and control mechanisms. However, Vision-LLMs have demonstrated susceptibilities against various types of adversarial attacks, which would compromise their reliability and safety. To further explore the risk in AD systems and the transferability of practical threats, we propose to leverage typographic attacks against AD systems relying on the decision-making capabilities of Vision-LLMs. Different from the few existing works developing general datasets of typographic attacks, this paper focuses on realistic traffic scenarios where these attacks can be deployed, on their potential effects on the decision-making autonomy, and on the practical ways in which these attacks can be physically presented. To achieve the above goals, we first propose a dataset-agnostic framework for automatically generating false answers that can mislead Vision-LLMs' reasoning. Then, we present a linguistic augmentation scheme that facilitates attacks at image-level and region-level reasoning, and we extend it with attack patterns against multiple reasoning tasks simultaneously. Based on these, we conduct a study on how these attacks can be realized in physical traffic scenarios. Through our empirical study, we evaluate the effectiveness, transferability, and realizability of typographic attacks in traffic scenes. Our findings demonstrate particular harmfulness of the typographic attacks against existing Vision-LLMs (e.g., LLaVA, Qwen-VL, VILA, and Imp), thereby raising community awareness of vulnerabilities when incorporating such models into AD systems. We will release our source code upon acceptance.