 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition
Paper and Code
Apr 21, 2022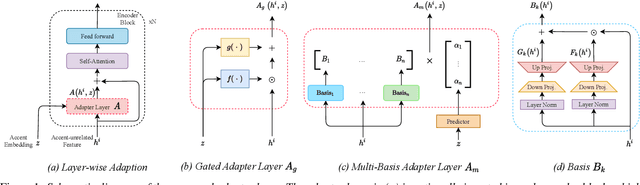
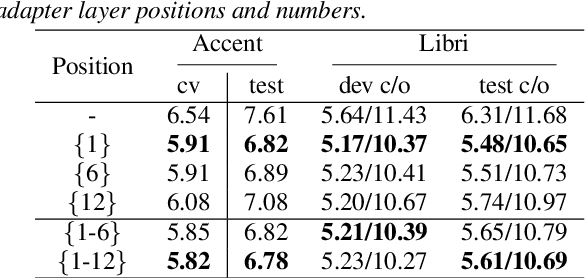
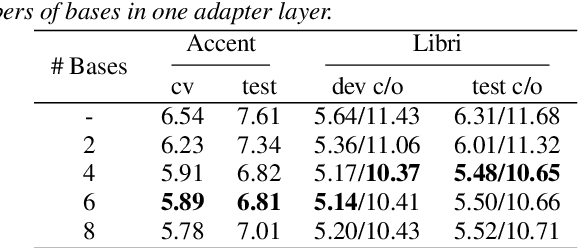
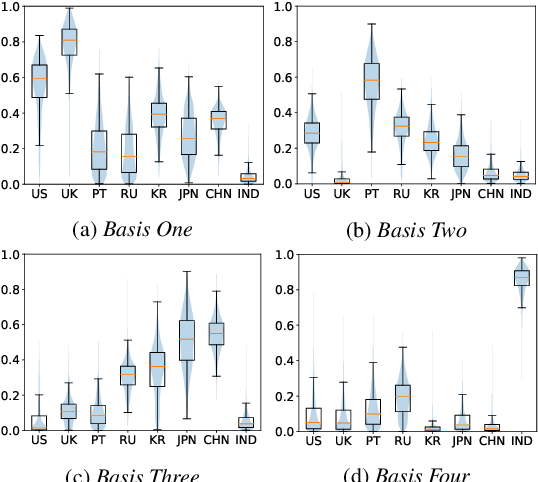
Accent variability has posed a huge challenge to automatic speech recognition~(ASR) modeling. Although one-hot accent vector based adaptation systems are commonly used, they require prior knowledge about the target accent and cannot handle unseen accents. Furthermore, simply concatenating accent embeddings does not make good use of accent knowledge, which has limited improvements. In this work, we aim to tackle these problems with a novel layer-wise adaptation structure injected into the E2E ASR model encoder. The adapter layer encodes an arbitrary accent in the accent space and assists the ASR model in recognizing accented speech. Given an utterance, the adaptation structure extracts the corresponding accent information and transforms the input acoustic feature into an accent-related feature through the linear combination of all accent bases. We further explore the injection position of the adaptation layer, the number of accent bases, and different types of accent bases to achieve better accent adaptation. Experimental results show that the proposed adaptation structure brings 12\% and 10\% relative word error rate~(WER) reduction on the AESRC2020 accent dataset and the Librispeech dataset, respectively, compared to the baseline.