 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Accented English Speech Recognition Challenge 2020: Open Datasets, Tracks, Baselines, Results and Methods
Feb 20, 2021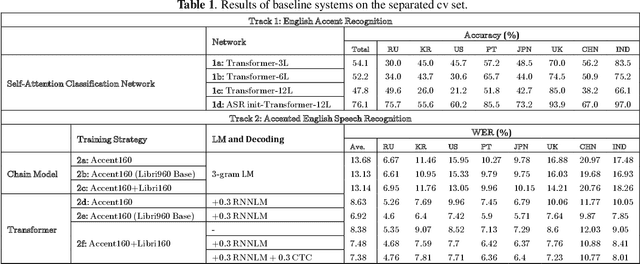
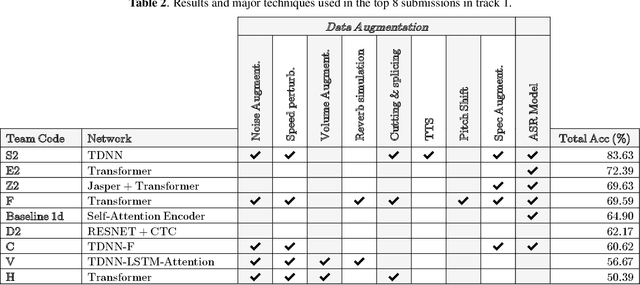
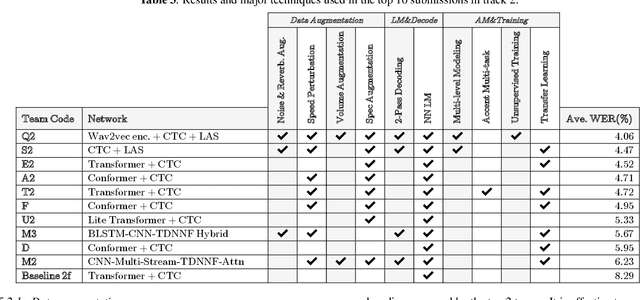
The variety of accents has posed a big challenge to speech recognition. The Accented English Speech Recognition Challenge (AESRC2020) is designed for providing a common testbed and promoting accent-related research. Two tracks are set in the challenge -- English accent recognition (track 1) and accented English speech recognition (track 2). A set of 160 hours of accented English speech collected from 8 countries is released with labels as the training set. Another 20 hours of speech without labels is later released as the test set, including two unseen accents from another two countries used to test the model generalization ability in track 2. We also provide baseline systems for the participants. This paper first reviews the released dataset, track setups, baselines and then summarizes the challenge results and major techniques used in the submissions.
The ASRU 2019 Mandarin-English Code-Switching Speech Recognition Challenge: Open Datasets, Tracks, Methods and Results
Jul 12, 2020



Code-switching (CS) is a common phenomenon and recognizing CS speech is challenging. But CS speech data is scarce and there' s no common testbed in relevant research. This paper describes the design and main outcomes of the ASRU 2019 Mandarin-English code-switching speech recognition challenge, which aims to improve the ASR performance in Mandarin-English code-switching situation. 500 hours Mandarin speech data and 240 hours Mandarin-English intra-sentencial CS data are released to the participants. Three tracks were set for advancing the AM and LM part in traditional DNN-HMM ASR system, as well as exploring the E2E models' performance. The paper then presents an overview of the results and system performance in the three tracks. It turns out that traditional ASR system benefits from pronunciation lexicon, CS text generating and data augmentation. In E2E track, however, the results highlight the importance of using language identification, building-up a rational set of modeling units and spec-augment. The other details in model training and method comparsion are discussed.