 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectQuote: A Dataset for Direct Quotation Extraction and Attribution in News Articles
Paper and Code
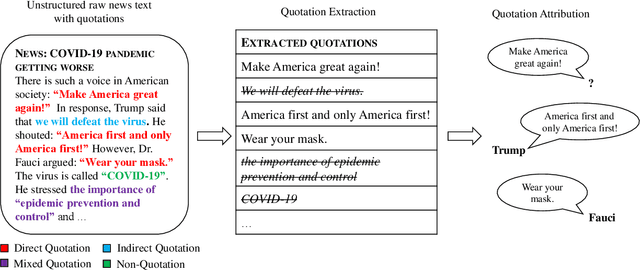
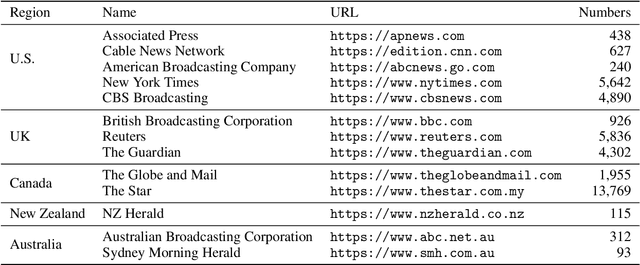


Quotation extraction and attribution are challenging tasks, aiming at determining the spans containing quotations and attributing each quotation to the original speaker. Applying this task to news data is highly related to fact-checking, media monitoring and news tracking. Direct quotations are more traceable and informative, and therefore of great significance among different types of quotations. Therefore, this paper introduces DirectQuote, a corpus containing 19,760 paragraphs and 10,279 direct quotations manually annotated from online news media. To the best of our knowledge, this is the largest and most complete corpus that focuses on direct quotations in news texts. We ensure that each speaker in the annotation can be linked to a specific named entity on Wikidata, benefiting various downstream tasks. In addition, for the first time, we propose several sequence labeling models as baseline methods to extract and attribute quotations simultaneously in an end-to-end manner.