 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinually Learning from Existing Models: Knowledge Accumulation for Neural Machine Translation
Paper and Code
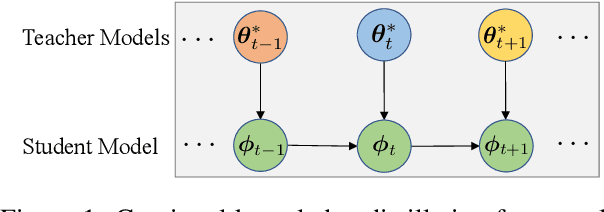
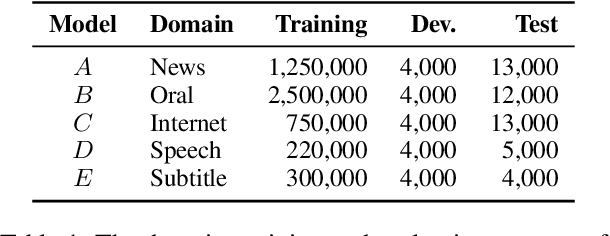
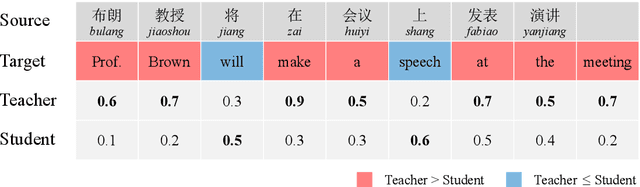
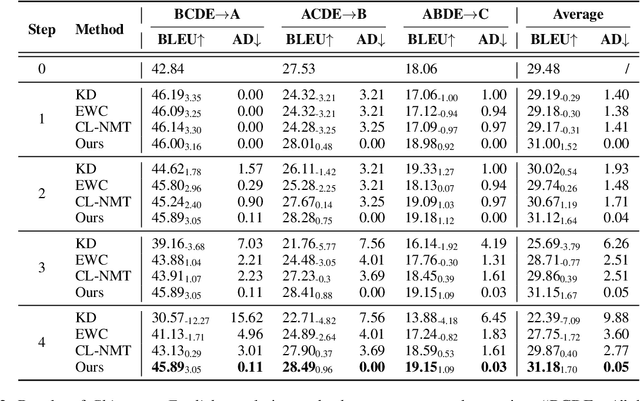
Although continually extending an existing NMT model to new domains or languages has attracted intensive interest in recent years, the equally valuable problem of continually improving a given NMT model in its domain by leveraging knowledge from an unlimited number of existing NMT models is not explored yet. To facilitate the study, we propose a formal definition for the problem named knowledge accumulation for NMT (KA-NMT) with corresponding datasets and evaluation metrics and develop a novel method for KA-NMT. We investigate a novel knowledge detection algorithm to identify beneficial knowledge from existing models at token level, and propose to learn from beneficial knowledge and learn against other knowledge simultaneously to improve learning efficiency. To alleviate catastrophic forgetting, we further propose to transfer knowledge from previous to current version of the given model. Extensive experiments show that our proposed method significantly and consistently outperforms representative baselines under homogeneous, heterogeneous, and malicious model settings for different language pairs.