 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Rethinking Multiple-Choice Questions for RLVR: Unlocking Potential via Distractor Design
Mar 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) significantly enhances the reasoning capabilities of Large Language Models. When applied to RLVR, Multiple-Choice Questions (MCQs) offer a scalable source of verifiable data but risk inducing reward hacking, where models shortcut reasoning via random guessing or simple elimination. Current approaches often mitigate this by converting MCQs to open-ended formats, thereby discarding the contrastive signal provided by expert-designed distractors. In this work, we systematically investigate the impact of option design on RLVR. Our analysis highlights two primary insights: (1) Mismatches in option counts between training and testing degrade performance. (2) Strong distractors effectively mitigate random guessing, enabling effective RLVR training even with 2-way questions. Motivated by these findings, we propose Iterative Distractor Curation (IDC), a framework that actively constructs high-quality distractors to block elimination shortcuts and promote deep reasoning. Experiments on various benchmarks demonstrate that our method effectively enhances distractor quality and yields significant gains in RLVR training compared to the original data.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
VideoRoPE: What Makes for Good Video Rotary Position Embedding?
Feb 07, 2025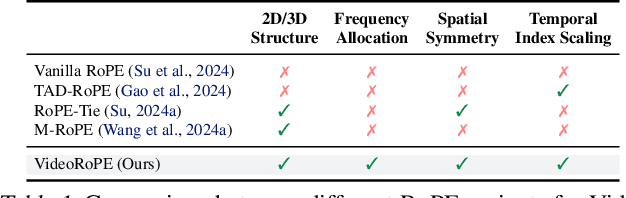
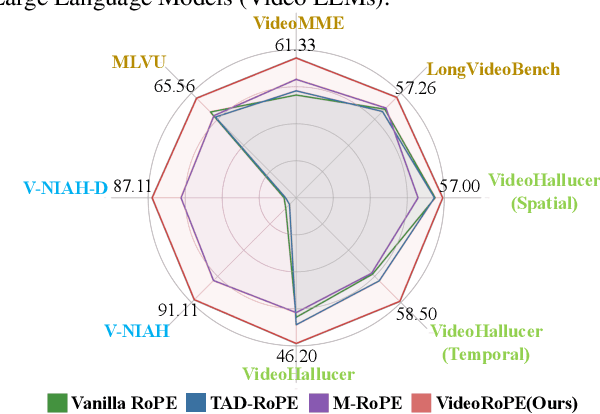
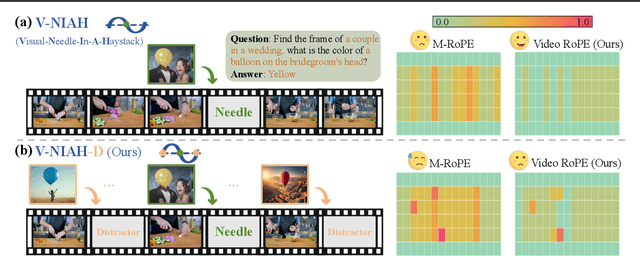
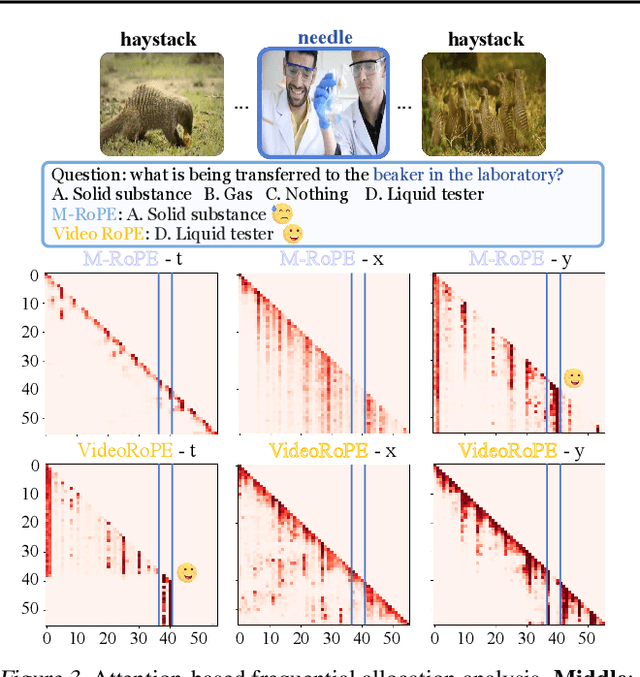
While Rotary Position Embedding (RoPE) and its variants are widely adopted for their long-context capabilities, the extension of the 1D RoPE to video, with its complex spatio-temporal structure, remains an open challenge. This work first introduces a comprehensive analysis that identifies four key characteristics essential for the effective adaptation of RoPE to video, which have not been fully considered in prior work. As part of our analysis, we introduce a challenging V-NIAH-D (Visual Needle-In-A-Haystack with Distractors) task, which adds periodic distractors into V-NIAH. The V-NIAH-D task demonstrates that previous RoPE variants, lacking appropriate temporal dimension allocation, are easily misled by distractors. Based on our analysis, we introduce \textbf{VideoRoPE}, with a \textit{3D structure} designed to preserve spatio-temporal relationships. VideoRoPE features \textit{low-frequency temporal allocation} to mitigate periodic oscillations, a \textit{diagonal layout} to maintain spatial symmetry, and \textit{adjustable temporal spacing} to decouple temporal and spatial indexing. VideoRoPE consistently surpasses previous RoPE variants, across diverse downstream tasks such as long video retrieval, video understanding, and video hallucination. Our code will be available at \href{https://github.com/Wiselnn570/VideoRoPE}{https://github.com/Wiselnn570/VideoRoPE}.
Improving speech translation by fusing speech and text
May 23, 2023In speech translation, leveraging multimodal data to improve model performance and address limitations of individual modalities has shown significant effectiveness. In this paper, we harness the complementary strengths of speech and text, which are disparate modalities. We observe three levels of modality gap between them, denoted by Modal input representation, Modal semantic, and Modal hidden states. To tackle these gaps, we propose \textbf{F}use-\textbf{S}peech-\textbf{T}ext (\textbf{FST}), a cross-modal model which supports three distinct input modalities for translation: speech, text, and fused speech-text. We leverage multiple techniques for cross-modal alignment and conduct a comprehensive analysis to assess its impact on speech translation, machine translation, and fused speech-text translation. We evaluate FST on MuST-C, GigaST, and newstest benchmark. Experiments show that the proposed FST achieves an average 34.0 BLEU on MuST-C En$\rightarrow$De/Es/Fr (vs SOTA +1.1 BLEU). Further experiments demonstrate that FST does not degrade on MT task, as observed in prior works. Instead, it yields an average improvement of 3.2 BLEU over the pre-trained MT model.
The Volctrans Neural Speech Translation System for IWSLT 2021
May 16, 2021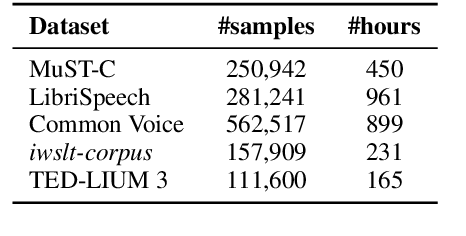
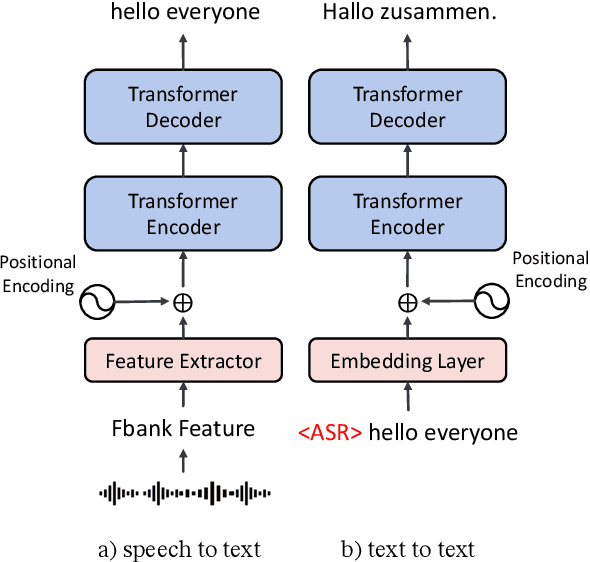
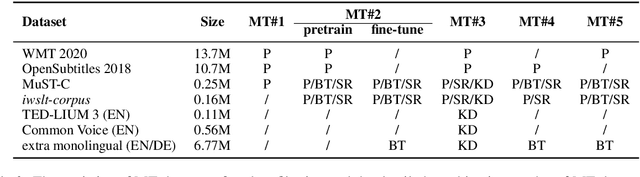
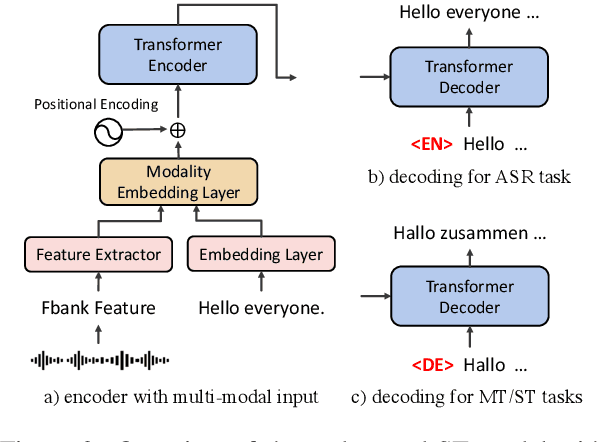
This paper describes the systems submitted to IWSLT 2021 by the Volctrans team. We participate in the offline speech translation and text-to-text simultaneous translation tracks. For offline speech translation, our best end-to-end model achieves 8.1 BLEU improvements over the benchmark on the MuST-C test set and is even approaching the results of a strong cascade solution. For text-to-text simultaneous translation, we explore the best practice to optimize the wait-k model. As a result, our final submitted systems exceed the benchmark at around 7 BLEU on the same latency regime. We will publish our code and model to facilitate both future research works and industrial applications.