 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fine-Tuning of Transformer-Based Language Models for Named Entity Recognition
Paper and Code



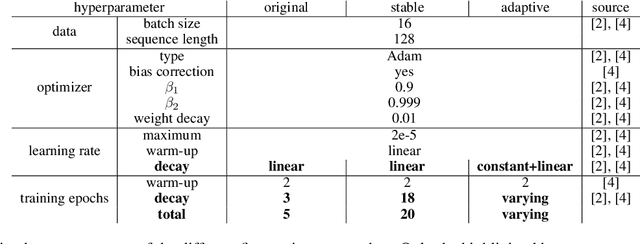
The current standard approach for fine-tuning transformer-based language models includes a fixed number of training epochs and a linear learning rate schedule. In order to obtain a near-optimal model for the given downstream task, a search in optimization hyperparameter space is usually required. In particular, the number of training epochs needs to be adjusted to the dataset size. In this paper, we introduce adaptive fine-tuning, which is an alternative approach that uses early stopping and a custom learning rate schedule to dynamically adjust the number of training epochs to the dataset size. For the example use case of named entity recognition, we show that our approach not only makes hyperparameter search with respect to the number of training epochs redundant, but also leads to improved results in terms of performance, stability and efficiency. This holds true especially for small datasets, where we outperform the state-of-the-art fine-tuning method by a large margin.