 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Begging: Modular and Efficient Shielding of LLMs against Prompt Injection and Jailbreaking based on Prompt Tuning
Jul 03, 2024Prompt injection (both direct and indirect) and jailbreaking are now recognized as significant issues for large language models (LLMs), particularly due to their potential for harm in application-integrated contexts. This extended abstract explores a novel approach to protecting LLMs from such attacks, termed "soft begging." This method involves training soft prompts to counteract the effects of corrupted prompts on the LLM's output. We provide an overview of prompt injections and jailbreaking, introduce the theoretical basis of the "soft begging" technique, and discuss an evaluation of its effectiveness.
More than you've asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models
Feb 23, 2023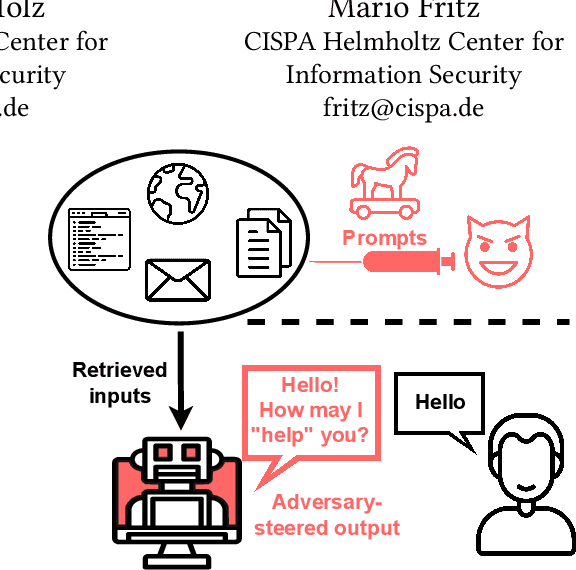
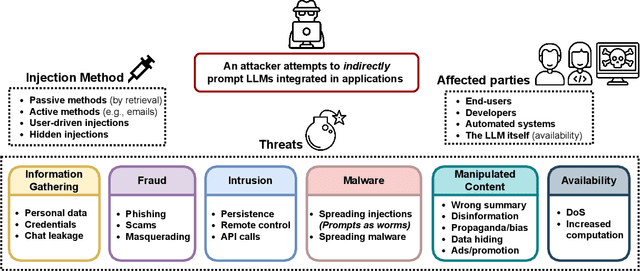
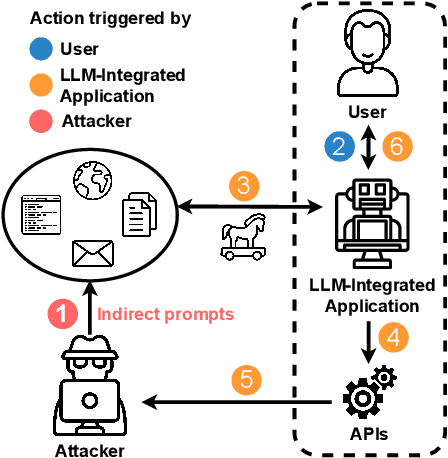
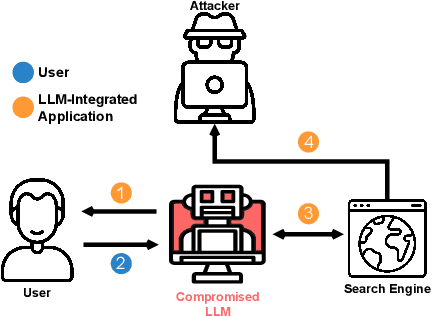
We are currently witnessing dramatic advances in the capabilities of Large Language Models (LLMs). They are already being adopted in practice and integrated into many systems, including integrated development environments (IDEs) and search engines. The functionalities of current LLMs can be modulated via natural language prompts, while their exact internal functionality remains implicit and unassessable. This property, which makes them adaptable to even unseen tasks, might also make them susceptible to targeted adversarial prompting. Recently, several ways to misalign LLMs using Prompt Injection (PI) attacks have been introduced. In such attacks, an adversary can prompt the LLM to produce malicious content or override the original instructions and the employed filtering schemes. Recent work showed that these attacks are hard to mitigate, as state-of-the-art LLMs are instruction-following. So far, these attacks assumed that the adversary is directly prompting the LLM. In this work, we show that augmenting LLMs with retrieval and API calling capabilities (so-called Application-Integrated LLMs) induces a whole new set of attack vectors. These LLMs might process poisoned content retrieved from the Web that contains malicious prompts pre-injected and selected by adversaries. We demonstrate that an attacker can indirectly perform such PI attacks. Based on this key insight, we systematically analyze the resulting threat landscape of Application-Integrated LLMs and discuss a variety of new attack vectors. To demonstrate the practical viability of our attacks, we implemented specific demonstrations of the proposed attacks within synthetic applications. In summary, our work calls for an urgent evaluation of current mitigation techniques and an investigation of whether new techniques are needed to defend LLMs against these threats.