 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semi-Supervised Multi-View Graph Convolutional Networks via Supervised Contrastive Learning and Self-Training
Dec 15, 2025



The advent of graph convolutional network (GCN)-based multi-view learning provides a powerful framework for integrating structural information from heterogeneous views, enabling effective modeling of complex multi-view data. However, existing methods often fail to fully exploit the complementary information across views, leading to suboptimal feature representations and limited performance. To address this, we propose MV-SupGCN, a semi-supervised GCN model that integrates several complementary components with clear motivations and mutual reinforcement. First, to better capture discriminative features and improve model generalization, we design a joint loss function that combines Cross-Entropy loss with Supervised Contrastive loss, encouraging the model to simultaneously minimize intra-class variance and maximize inter-class separability in the latent space. Second, recognizing the instability and incompleteness of single graph construction methods, we combine both KNN-based and semi-supervised graph construction approaches on each view, thereby enhancing the robustness of the data structure representation and reducing generalization error. Third, to effectively utilize abundant unlabeled data and enhance semantic alignment across multiple views, we propose a unified framework that integrates contrastive learning in order to enforce consistency among multi-view embeddings and capture meaningful inter-view relationships, together with pseudo-labeling, which provides additional supervision applied to both the cross-entropy and contrastive loss functions to enhance model generalization. Extensive experiments demonstrate that MV-SupGCN consistently surpasses state-of-the-art methods across multiple benchmarks, validating the effectiveness of our integrated approach. The source code is available at https://github.com/HuaiyuanXiao/MVSupGCN
An Empirical Study on the Joint Impact of Feature Selection and Data Resampling on Imbalance Classification
Sep 01, 2021

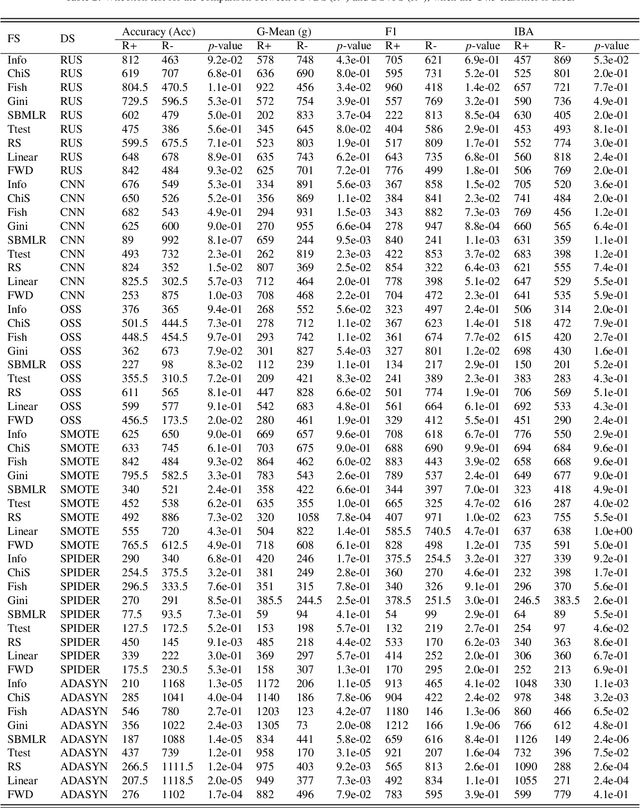

Real-world datasets often present different degrees of imbalanced (i.e., long-tailed or skewed) distributions. While the majority (a.k.a., head or frequent) classes have sufficient samples, the minority (a.k.a., tail or rare) classes can be under-represented by a rather limited number of samples. On one hand, data resampling is a common approach to tackling class imbalance. On the other hand, dimension reduction, which reduces the feature space, is a conventional machine learning technique for building stronger classification models on a dataset. However, the possible synergy between feature selection and data resampling for high-performance imbalance classification has rarely been investigated before. To address this issue, this paper carries out a comprehensive empirical study on the joint influence of feature selection and resampling on two-class imbalance classification. Specifically, we study the performance of two opposite pipelines for imbalance classification, i.e., applying feature selection before or after data resampling. We conduct a large amount of experiments (a total of 9225 experiments) on 52 publicly available datasets, using 9 feature selection methods, 6 resampling approaches for class imbalance learning, and 3 well-known classification algorithms. Experimental results show that there is no constant winner between the two pipelines, thus both of them should be considered to derive the best performing model for imbalance classification. We also find that the performance of an imbalance classification model depends on the classifier adopted, the ratio between the number of majority and minority samples (IR), as well as on the ratio between the number of samples and features (SFR). Overall, this study should provide new reference value for researchers and practitioners in imbalance learning.